笔者期望通过一篇权威靠谱、清晰易懂的系统性文章,帮助读者深入理解 Raft 算法,并能付诸于工程实践中,同时解读不易理解或容易误解的关键点。
本文是 Raft 实战系列理论内容的整合篇,我们结合 Raft 论文讲解 Raft 算法思路,并遵循 Raft 的模块化思想对难理解及容易误解的内容抽丝剥茧。算法方面讲解:选主机制、基于日志实现状态机机制、安全正确维护状态机机制;工程实现方面讲解:集群成员变更防脑裂策略、解决数据膨胀及快速恢复状态机策略、线性一致读性能优化策略等。
1. 概述
1.1 Raft 是什么?
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems.
–《In Search of an Understandable Consensus Algorithm》
在分布式系统中,为了消除单点提高系统可用性,通常会使用副本来进行容错,但这会带来另一个问题,即如何保证多个副本之间的一致性?
这里我们只讨论强一致性,即线性一致性。弱一致性涵盖的范围较广,涉及根据实际场景进行诸多取舍,不在 Raft 系列的讨论目标范围内。
所谓的强一致性(线性一致性)并不是指集群中所有节点在任一时刻的状态必须完全一致,而是指一个目标,即让一个分布式系统看起来只有一个数据副本,并且读写操作都是原子的,这样应用层就可以忽略系统底层多个数据副本间的同步问题。也就是说,我们可以将一个强一致性分布式系统当成一个整体,一旦某个客户端成功的执行了写操作,那么所有客户端都一定能读出刚刚写入的值。即使发生网络分区故障,或者少部分节点发生异常,整个集群依然能够像单机一样提供服务。
共识算法(Consensus Algorithm)就是用来做这个事情的,它保证即使在小部分(≤ (N-1)/2)节点故障的情况下,系统仍然能正常对外提供服务。共识算法通常基于状态复制机(Replicated State Machine)模型,也就是所有节点从同一个 state 出发,经过同样的操作 log,最终达到一致的 state。
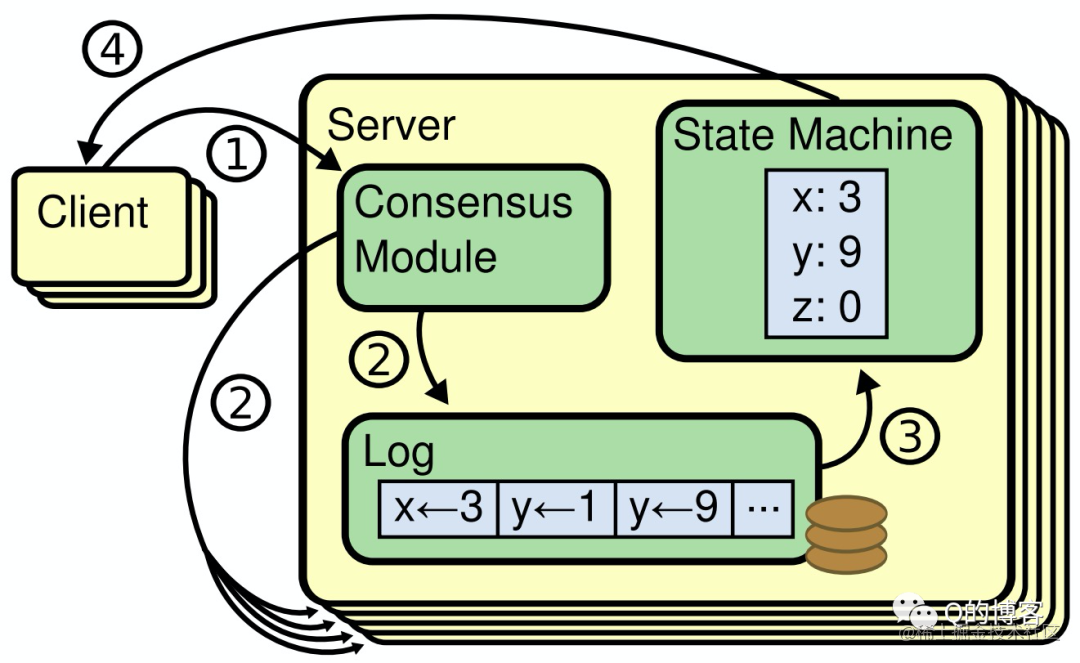 图:Replicated State Machine
图:Replicated State Machine
共识算法是构建强一致性分布式系统的基石,Paxos 是共识算法的代表,而 Raft 则是其作者在博士期间研究 Paxos 时提出的一个变种,主要优点是容易理解、易于实现,甚至关键的部分都在论文中给出了伪代码实现。
1.2 谁在使用 Raft
采用 Raft 的系统最著名的当属 etcd 了,可以认为 etcd 的核心就是 Raft 算法的实现。作为一个分布式 kv 系统,etcd 使用 Raft 在多节点间进行数据同步,每个节点都拥有全量的状态机数据。我们在学习了 Raft 以后将会深刻理解为什么 etcd 不适合大数据量的存储(for the most critical data)、为什么集群节点数不是越多越好、为什么集群适合部署奇数个节点等问题。
作为一个微服务基础设施,consul 底层使用 Raft 来保证 consul server 之间的数据一致性。在阅读完第六章后,我们会理解为什么 consul 提供了 default、consistent、stale 三种一致性模式(Consistency Modes)、它们各自适用的场景,以及 consul 底层是如何通过改变 Raft 读模型来支撑这些不同的一致性模式的。
TiKV 同样在底层使用了 Raft 算法。虽然都自称是“分布式 kv 存储”,但 TiKV 的使用场景与 etcd 存在区别。其目标是支持 100TB+ 的数据,类似 etcd 的单 Raft 集群肯定无法支撑这个数据量。因此 TiKV 底层使用 Multi Raft,将数据划分为多个 region,每个 region 其实还是一个标准的 Raft 集群,对每个分区的数据实现了多副本高可用。
目前 Raft 在工业界已经开始大放异彩,对于其各类应用场景这里不再赘述,感兴趣的读者可以参考 这里,下方有列出各种语言的大量 Raft 实现。
1.3 Raft 基本概念
Raft 使用 Quorum 机制来实现共识和容错,我们将对 Raft 集群的操作称为提案,每当发起一个提案,必须得到大多数(> N/2)节点的同意才能提交。
这里的“提案”我们可以先狭义地理解为对集群的读写操作,“提交”理解为操作成功。
那么当我们向 Raft 集群发起一系列读写操作时,集群内部究竟发生了什么呢?我们先来概览式地做一个整体了解,接下来再分章节详细介绍每个部分。
首先,Raft 集群必须存在一个主节点(leader),我们作为客户端向集群发起的所有操作都必须经由主节点处理。所以 Raft 核心算法中的第一部分就是选主(Leader election)——没有主节点集群就无法工作,先票选出一个主节点,再考虑其它事情。
其次,主节点需要承载什么工作呢?它会负责接收客户端发过来的操作请求,将操作包装为日志同步给其它节点,在保证大部分节点都同步了本次操作后,就可以安全地给客户端回应响应了。这一部分工作在 Raft 核心算法中叫日志复制(Log replication)。
然后,因为主节点的责任是如此之大,所以节点们在选主的时候一定要谨慎,只有符合条件的节点才可以当选主节点。此外主节点在处理操作日志的时候也一定要谨慎,为了保证集群对外展现的一致性,不可以覆盖或删除前任主节点已经处理成功的操作日志。所谓的“谨慎处理”,其实就是在选主和提交日志的时候进行一些限制,这一部分在 Raft 核心算法中叫安全性(Safety)。
Raft 核心算法其实就是由这三个子问题组成的:选主(Leader election)、日志复制(Log replication)、安全性(Safety)。这三部分共同实现了 Raft 核心的共识和容错机制。
除了核心算法外,Raft 也提供了几个工程实践中必须面对问题的解决方案。
第一个是关于日志无限增长的问题。Raft 将操作包装成为了日志,集群每个节点都维护了一个不断增长的日志序列,状态机只有通过重放日志序列来得到。但由于这个日志序列可能会随着时间流逝不断增长,因此我们必须有一些办法来避免无休止的磁盘占用和过久的日志重放。这一部分叫日志压缩(Log compaction)。
第二个是关于集群成员变更的问题。一个 Raft 集群不太可能永远是固定几个节点,总有扩缩容的需求,或是节点宕机需要替换的时候。直接更换集群成员可能会导致严重的脑裂问题。Raft 给出了一种安全变更集群成员的方式。这一部分叫集群成员变更(Cluster membership change)。
此外,我们还会额外讨论线性一致性的定义、为什么 Raft 不能与线性一致划等号、如何基于 Raft 实现线性一致,以及在如何保证线性一致的前提下进行读性能优化。
以上便是理论篇内将会讨论到的大部分内容的概要介绍,这里我们对 Raft 已经有了一个宏观上的认识,知道了各个部分大概是什么内容,以及它们之间的关系。
接下来我们将会详细讨论 Raft 算法的每个部分。让我们先从第一部分选主开始。
2. 选主
2.1 什么是选主
选主(Leader election)就是在分布式系统内抉择出一个主节点来负责一些特定的工作。在执行了选主过程后,集群中每个节点都会识别出一个特定的、唯一的节点作为 leader。
我们开发的系统如果遇到选主的需求,通常会直接基于 zookeeper 或 etcd 来做,把这部分的复杂性收敛到第三方系统。然而作为 etcd 基础的 Raft 自身也存在“选主”的概念,这是两个层面的事情:基于 etcd 的选主指的是利用第三方 etcd 让集群对谁做主节点的决策达成一致,技术上来说利用的是 etcd 的一致性状态机、lease 以及 watch 机制,这个事情也可以改用单节点的 MySQL/Redis 来做,只是无法获得高可用性;而 Raft 本身的选主则指的是在 Raft 集群自身内部通过票选、心跳等机制来协调出一个大多数节点认可的主节点作为集群的 leader 去协调所有决策。
当你的系统利用 etcd 来写入谁是主节点的时候,这个决策也在 etcd 内部被它自己集群选出的主节点处理并同步给其它节点。
2.2 Raft 为什么要进行选主?
按照论文所述,原生的 Paxos 算法使用了一种点对点(peer-to-peer)的方式,所有节点地位是平等的。在理想情况下,算法的目的是制定一个决策,这对于简化的模型比较有意义。但在工业界很少会有系统会使用这种方式,当有一系列的决策需要被制定的时候,先选出一个 leader 节点然后让它去协调所有的决策,这样算法会更加简单快速。
此外,和其它一致性算法相比,Raft 赋予了 leader 节点更强的领导力,称之为 Strong Leader。比如说日志条目只能从 leader 节点发送给其它节点而不能反着来,这种方式简化了日志复制的逻辑,使 Raft 变得更加简单易懂。
2.3 Raft 选主过程
2.3.1 节点角色
Raft 集群中每个节点都处于以下三种角色之一:
- Leader: 所有请求的处理者,接收客户端发起的操作请求,写入本地日志后同步至集群其它节点。
- Follower: 请求的被动更新者,从 leader 接收更新请求,写入本地文件。如果客户端的操作请求发送给了 follower,会首先由 follower 重定向给 leader。
- Candidate: 如果 follower 在一定时间内没有收到 leader 的心跳,则判断 leader 可能已经故障,此时启动 leader election 过程,本节点切换为 candidate 直到选主结束。
2.3.2 任期
每开始一次新的选举,称为一个任期(term),每个 term 都有一个严格递增的整数与之关联。
每当 candidate 触发 leader election 时都会增加 term,如果一个 candidate 赢得选举,他将在本 term 中担任 leader 的角色。但并不是每个 term 都一定对应一个 leader,有时候某个 term 内会由于选举超时导致选不出 leader,这时 candicate 会递增 term 号并开始新一轮选举。
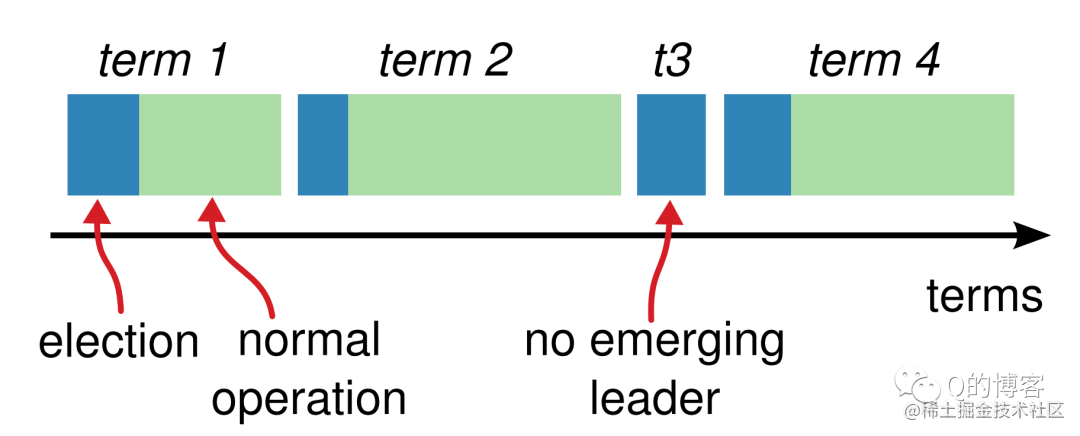
Term 更像是一个逻辑时钟(logic clock)的作用,有了它,就可以发现哪些节点的状态已经过期。每一个节点都保存一个 current term,在通信时带上这个 term 号。
节点间通过 RPC 来通信,主要有两类 RPC 请求:
- RequestVote RPCs: 用于 candidate 拉票选举。
- AppendEntries RPCs: 用于 leader 向其它节点复制日志以及同步心跳。
2.3.3 节点状态转换
我们知道集群每个节点的状态都只能是 leader、follower 或 candidate,那么节点什么时候会处于哪种状态呢?下图展示了一个节点可能发生的状态转换:
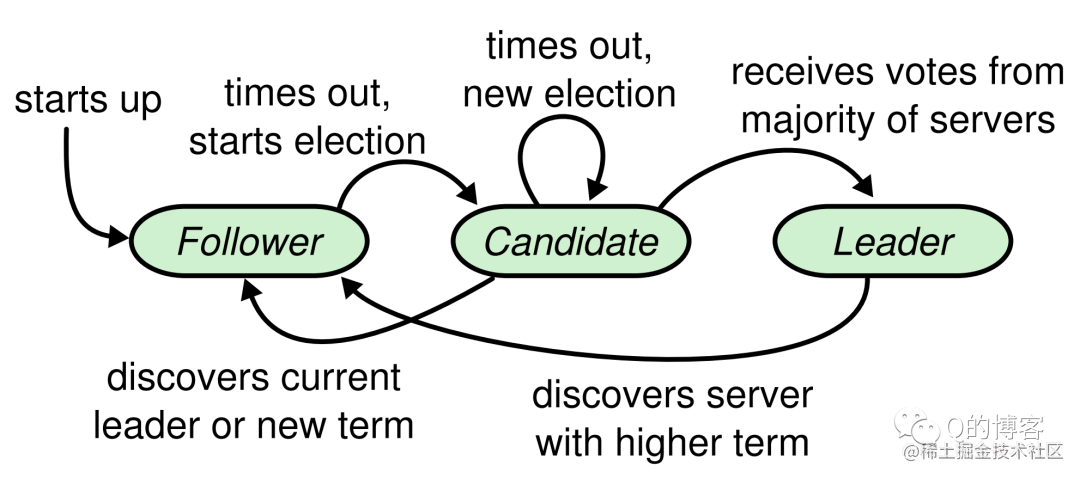
接下来我们详细讨论下每个转换所发生的场景。
2.3.3.1 Follower 状态转换过程
Raft 的选主基于一种心跳机制,集群中每个节点刚启动时都是 follower 身份(Step: starts up),leader 会周期性的向所有节点发送心跳包来维持自己的权威,那么首个 leader 是如何被选举出来的呢?方法是如果一个 follower 在一段时间内没有收到任何心跳,也就是选举超时,那么它就会主观认为系统中没有可用的 leader,并发起新的选举(Step: times out, starts election)。
这里有一个问题,即这个“选举超时时间”该如何制定?如果所有节点在同一时刻启动,经过同样的超时时间后同时发起选举,整个集群会变得低效不堪,极端情况下甚至会一直选不出一个主节点。Raft 巧妙的使用了一个随机化的定时器,让每个节点的“超时时间”在一定范围内随机生成,这样就大大的降低了多个节点同时发起选举的可能性。
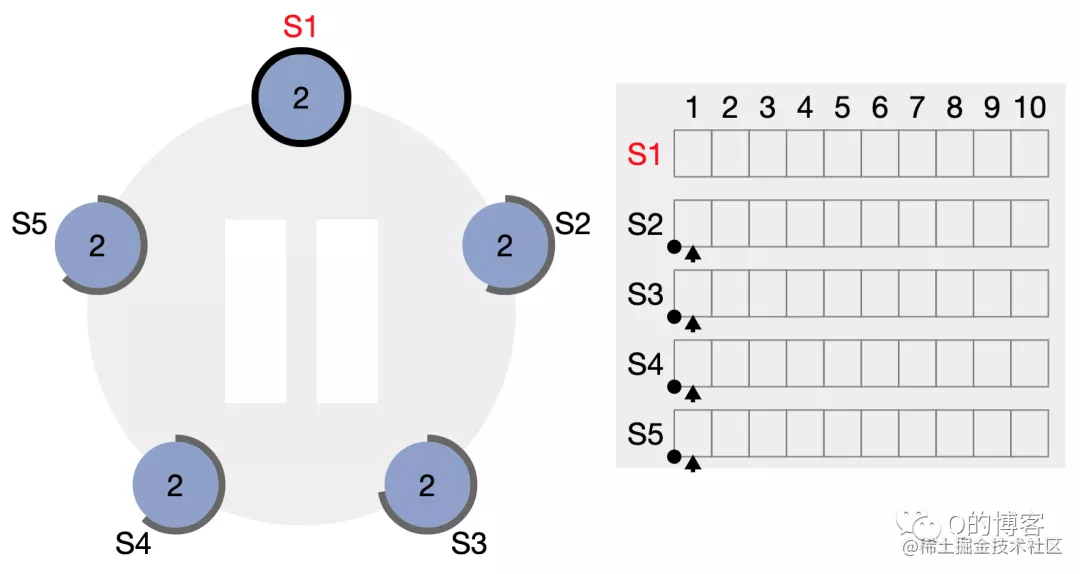
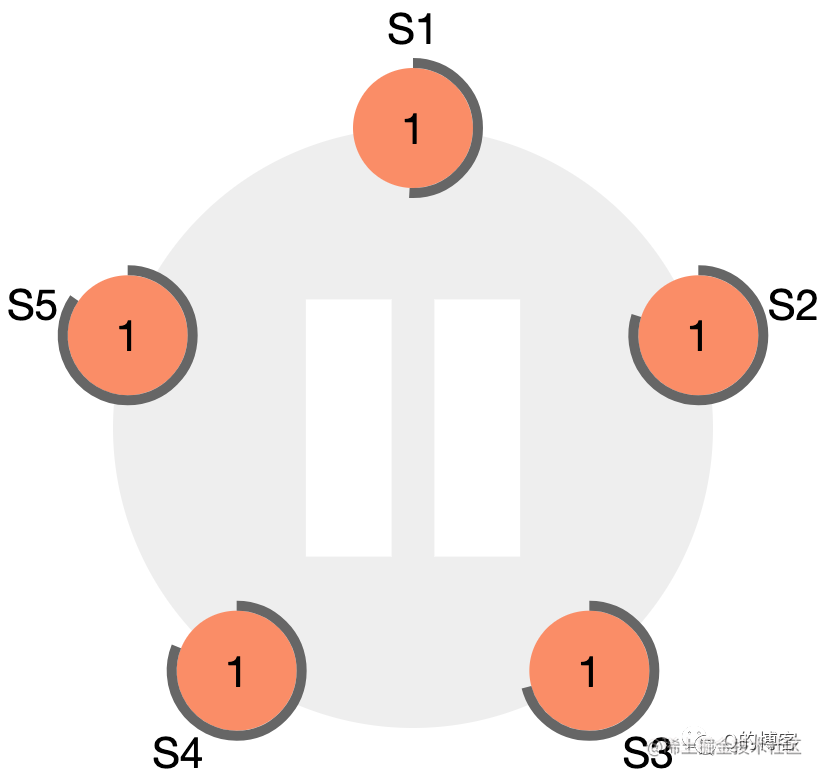 图:一个五节点 Raft 集群的初始状态,所有节点都是 follower 身份,term 为 1,且每个节点的选举超时定时器不同
图:一个五节点 Raft 集群的初始状态,所有节点都是 follower 身份,term 为 1,且每个节点的选举超时定时器不同
若 follower 想发起一次选举,follower 需要先增加自己的当前 term,并将身份切换为 candidate。然后它会向集群其它节点发送“请给自己投票”的消息(RequestVote RPC)。
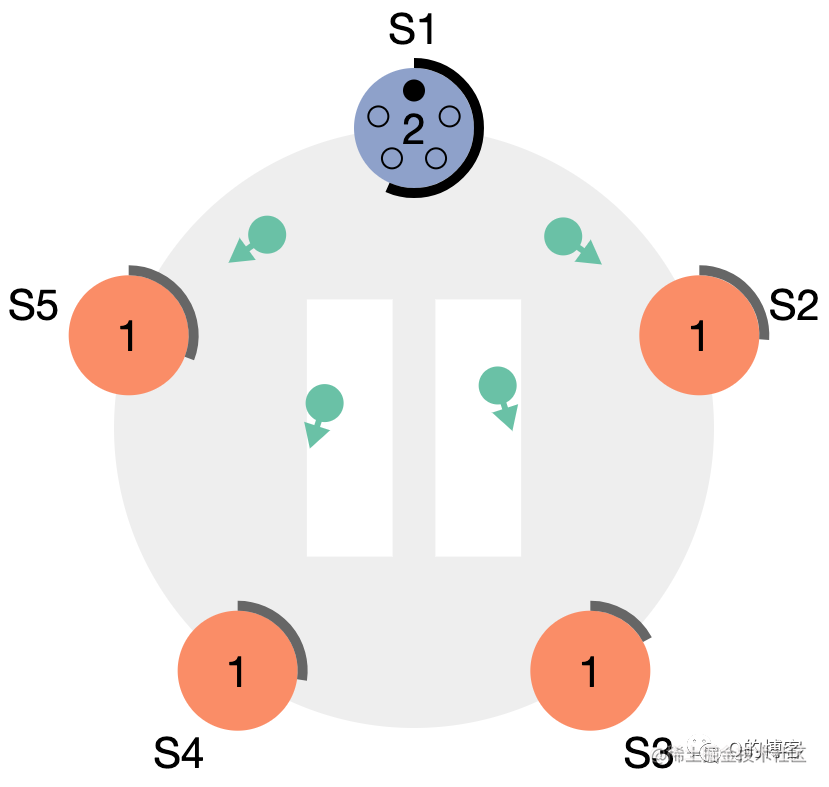 图:S1 率先超时,变为 candidate,term + 1,并向其它节点发出拉票请求
图:S1 率先超时,变为 candidate,term + 1,并向其它节点发出拉票请求
2.3.3.2 Candicate 状态转换过程
Follower 切换为 candidate 并向集群其他节点发送“请给自己投票”的消息后,接下来会有三种可能的结果,也即上面节点状态图中 candidate 状态向外伸出的三条线。
1. 选举成功(Step: receives votes from majority of servers)
当candicate从整个集群的大多数(N/2+1)节点获得了针对同一 term 的选票时,它就赢得了这次选举,立刻将自己的身份转变为 leader 并开始向其它节点发送心跳来维持自己的权威。
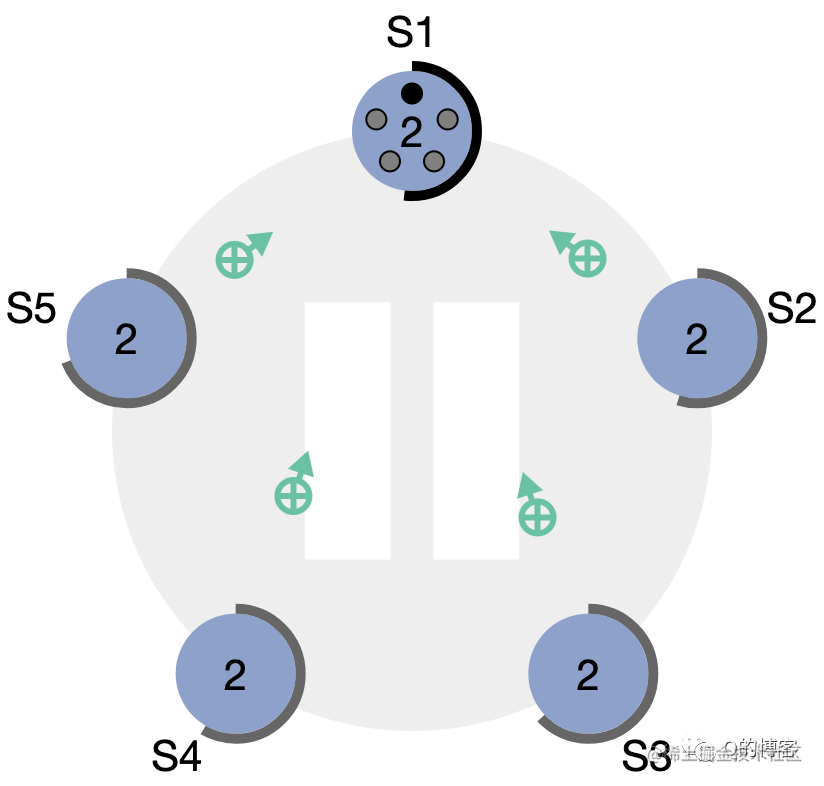 图:“大部分”节点都给了 S1 选票
图:“大部分”节点都给了 S1 选票
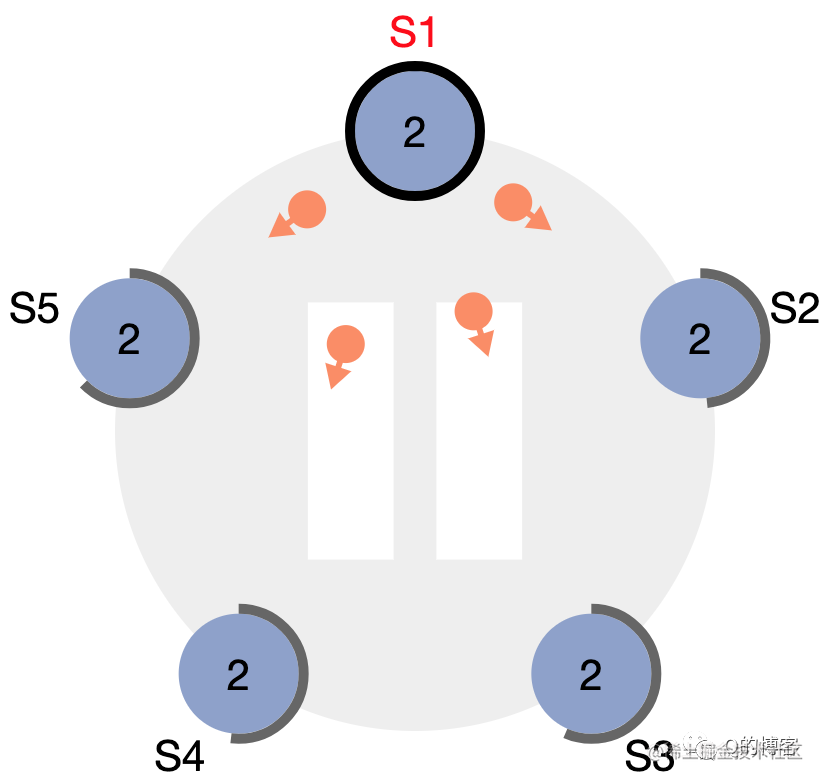 图:S1 变为 leader,开始发送心跳维持权威
图:S1 变为 leader,开始发送心跳维持权威
每个节点针对每个 term 只能投出一张票,并且按照先到先得的原则。这个规则确保只有一个 candidate 会成为 leader。
2. 选举失败(Step: discovers current leader or new term)
Candidate 在等待投票回复的时候,可能会突然收到其它自称是 leader 的节点发送的心跳包,如果这个心跳包里携带的 term 不小于 candidate 当前的 term,那么 candidate 会承认这个 leader,并将身份切回 follower。这说明其它节点已经成功赢得了选举,我们只需立刻跟随即可。但如果心跳包中的 term 比自己小,candidate 会拒绝这次请求并保持选举状态。
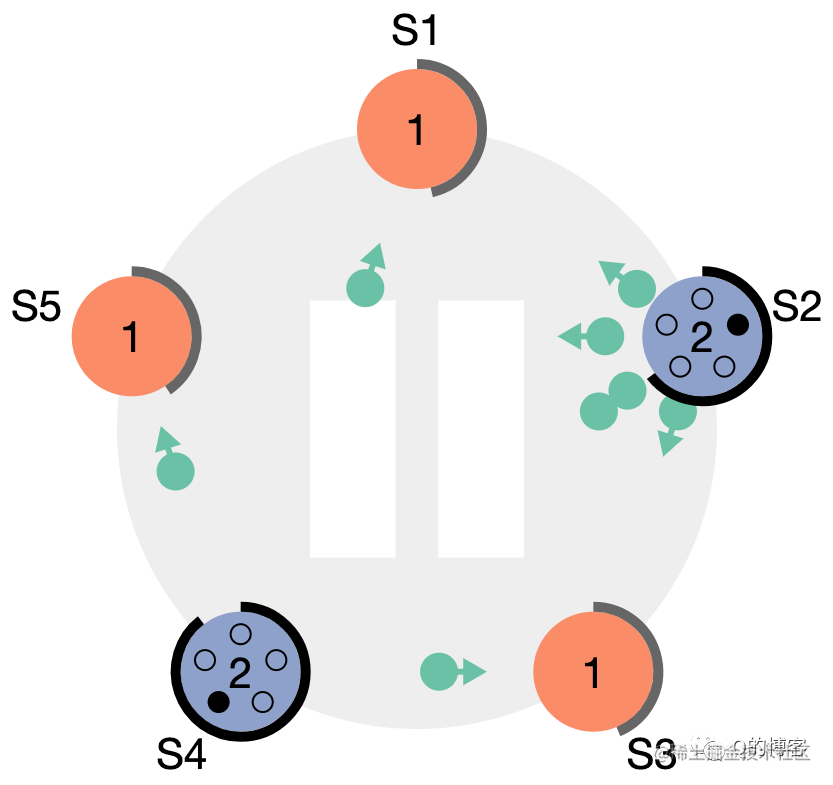 图:S4、S2 依次开始选举
图:S4、S2 依次开始选举
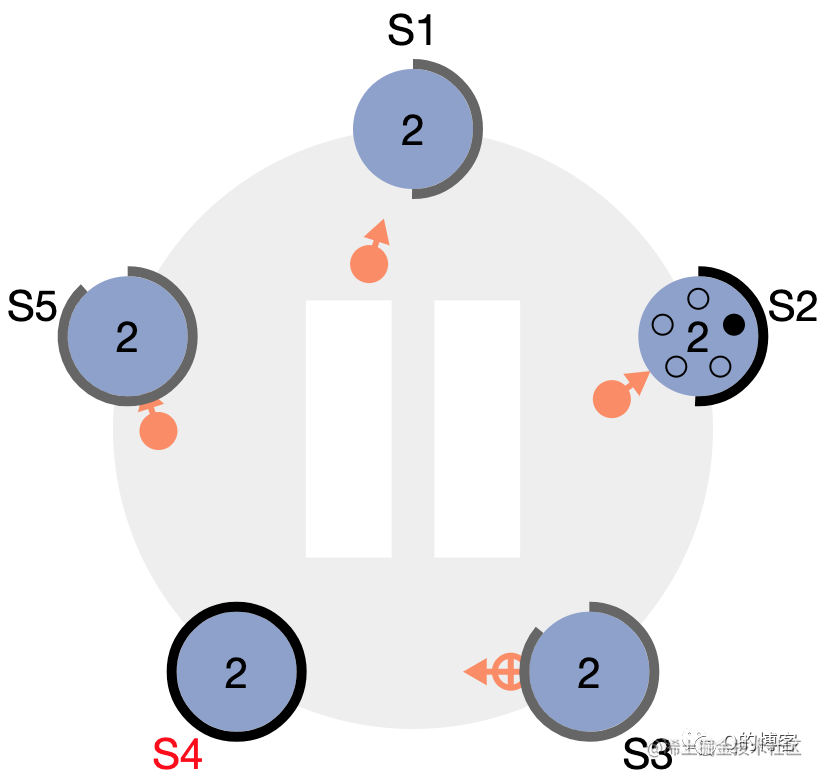 图:S4 成为 leader,S2 在收到 S4 的心跳包后,由于 term 不小于自己当前的 term,因此会立刻切为 follower 跟随 S4
图:S4 成为 leader,S2 在收到 S4 的心跳包后,由于 term 不小于自己当前的 term,因此会立刻切为 follower 跟随 S4
3. 选举超时(Step: times out, new election)
第三种可能的结果是 candidate 既没有赢也没有输。如果有多个 follower 同时成为 candidate,选票是可能被瓜分的,如果没有任何一个 candidate 能得到大多数节点的支持,那么每一个 candidate 都会超时。此时 candidate 需要增加自己的 term,然后发起新一轮选举。如果这里不做一些特殊处理,选票可能会一直被瓜分,导致选不出 leader 来。这里的“特殊处理”指的就是前文所述的随机化选举超时时间。
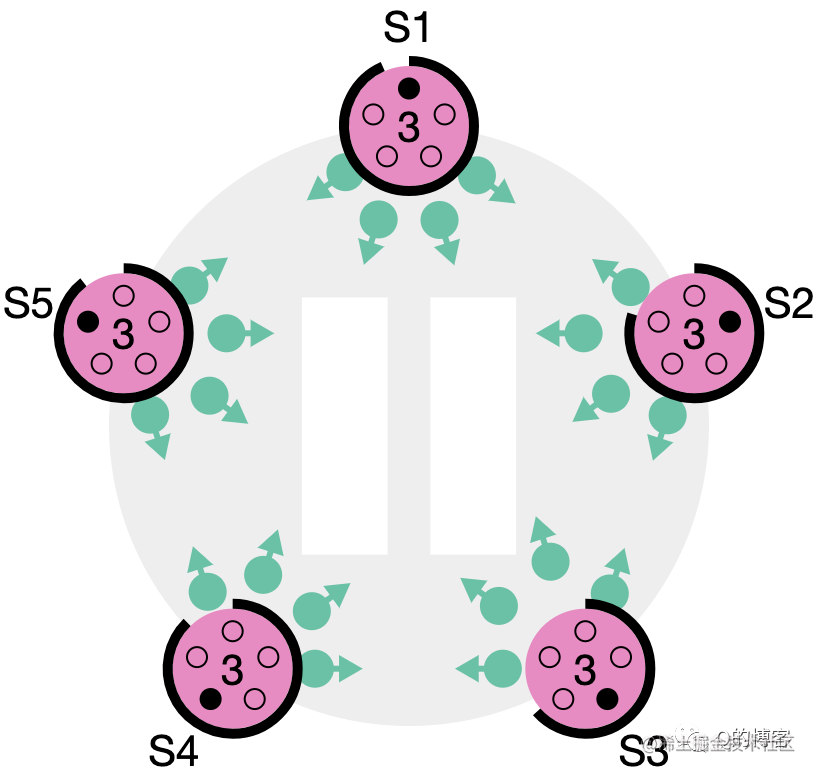 图:S1 ~ S5 都在参与选举
图:S1 ~ S5 都在参与选举
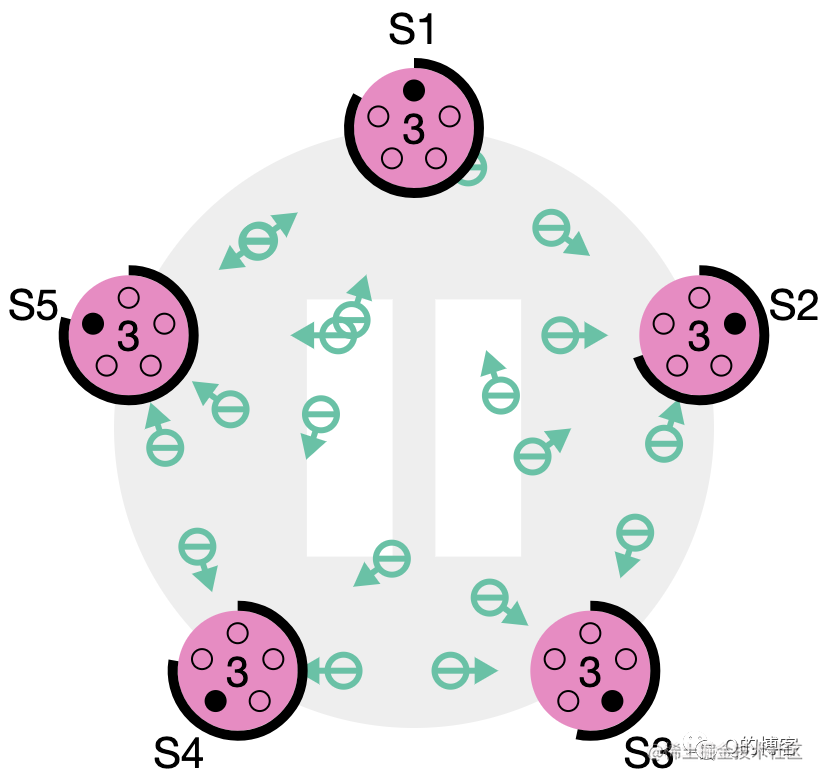 图:没有任何节点愿意给他人投票
图:没有任何节点愿意给他人投票
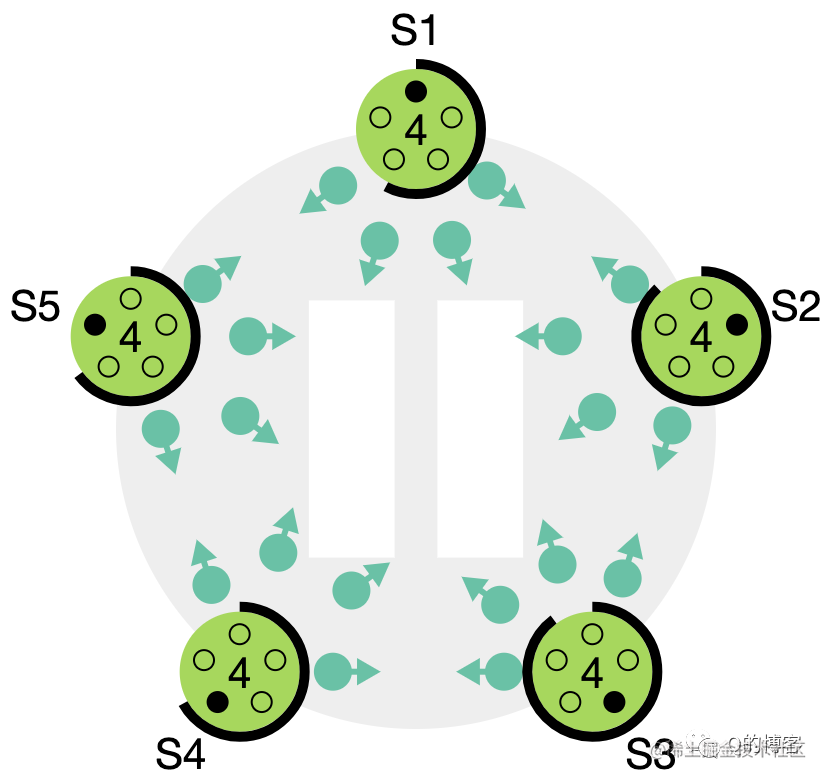 图:如果没有随机化超时时间,所有节点将会继续同时发起选举……
图:如果没有随机化超时时间,所有节点将会继续同时发起选举……
以上便是 candidate 三种可能的选举结果。
2.3.3.3 Leader 状态转换过程
节点状态图中的最后一条线是:discovers server with higher term。想象一个场景:当 leader 节点发生了宕机或网络断连,此时其它 follower 会收不到 leader 心跳,首个触发超时的节点会变为 candidate 并开始拉票(由于随机化各个 follower 超时时间不同),由于该 candidate 的 term 大于原 leader 的 term,因此所有 follower 都会投票给它,这名 candidate 会变为新的 leader。一段时间后原 leader 恢复了,收到了来自新leader 的心跳包,发现心跳中的 term 大于自己的 term,此时该节点会立刻切换为 follower 并跟随的新 leader。
上述流程的动画模拟如下:
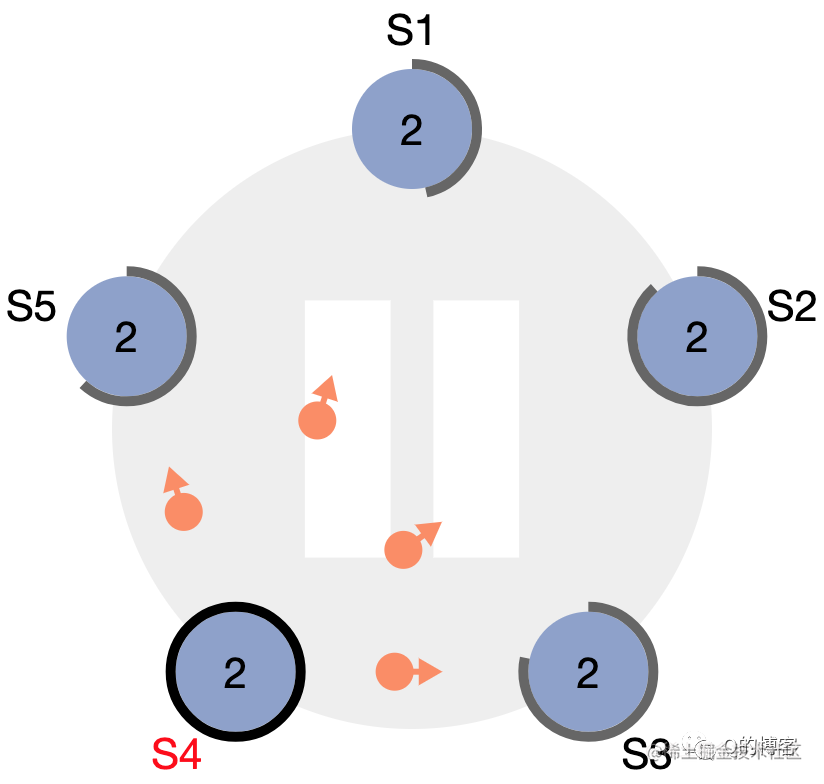 图:S4 作为 term2 的 leader
图:S4 作为 term2 的 leader
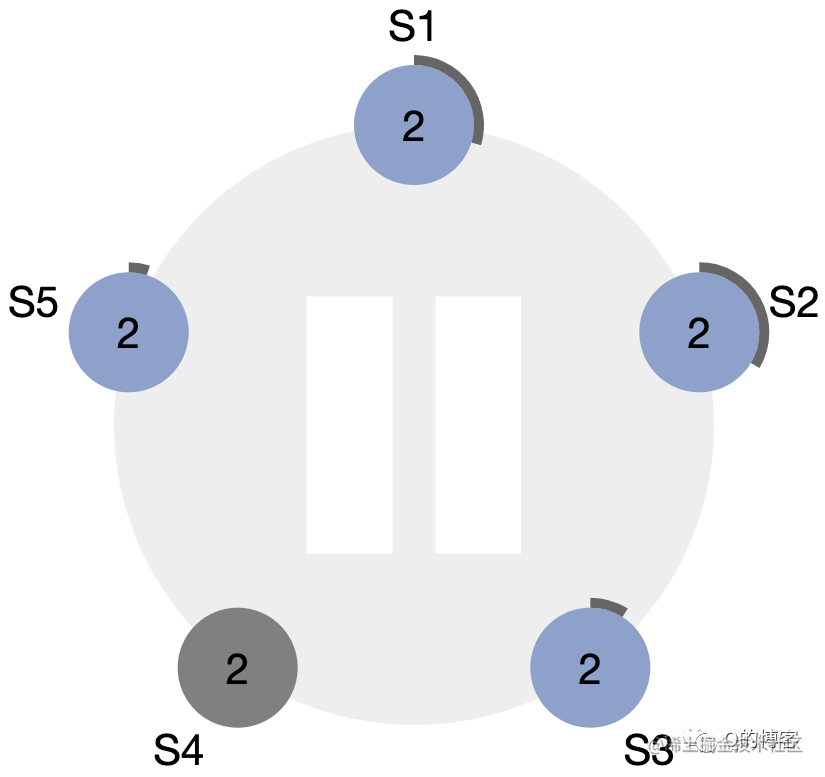 图:S4 宕机,S5 即将率先超时
图:S4 宕机,S5 即将率先超时
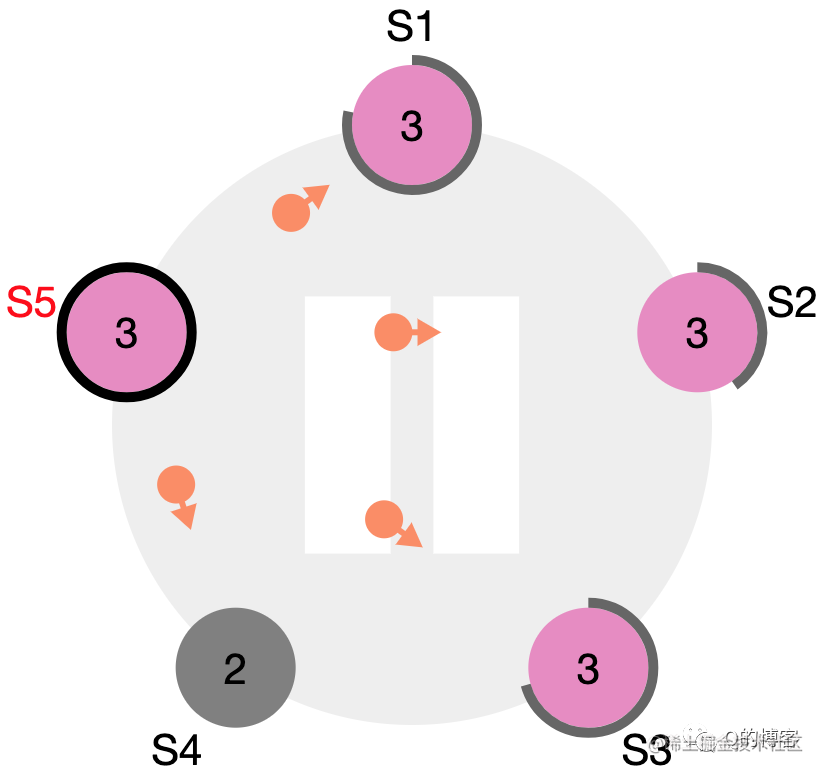 图:S5 当选 term3 的 leader
图:S5 当选 term3 的 leader
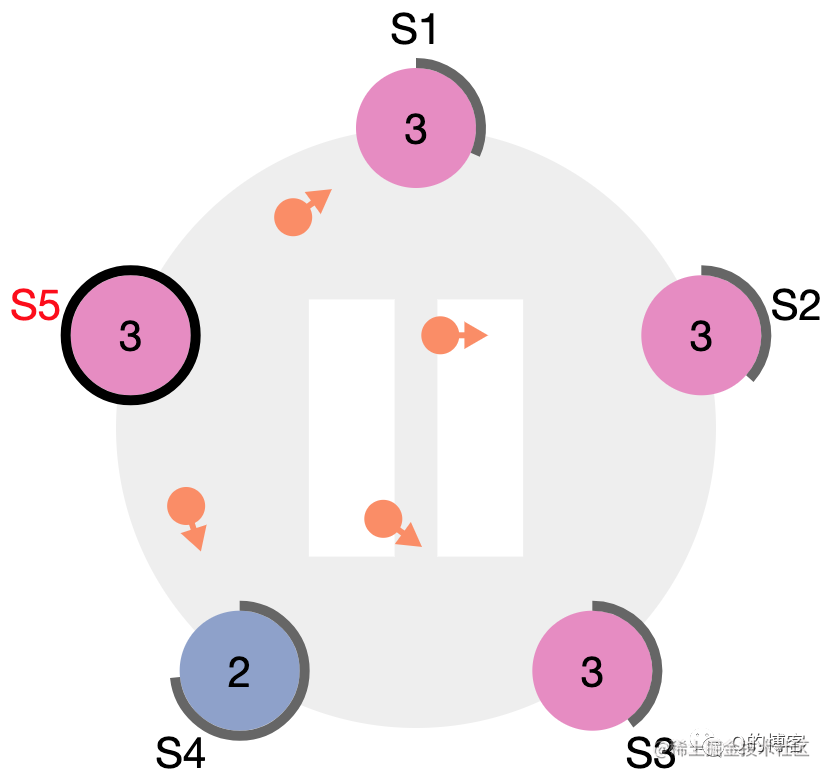 图:S4 宕机恢复后收到了来自 S5 的 term3 心跳
图:S4 宕机恢复后收到了来自 S5 的 term3 心跳
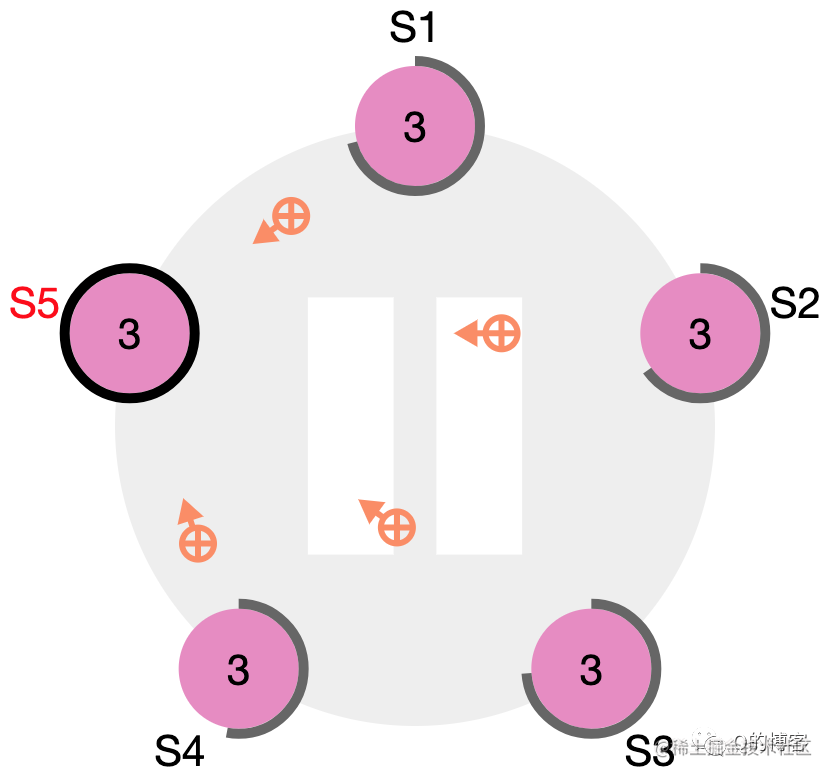 图:S4 立刻变为 S5 的 follower
图:S4 立刻变为 S5 的 follower
以上就是 Raft 的选主逻辑,但还有一些细节(譬如是否给该 candidate 投票还有一些其它条件)依赖算法的其它部分基础,我们会在后续“安全性”一章描述。
当票选出 leader 后,leader 也该承担起相应的责任了,这个责任是什么?就是下一章将介绍的“日志复制”。
3. 日志复制
3.1 什么是日志复制
在前文中我们讲过:共识算法通常基于状态复制机(Replicated State Machine)模型,所有节点从同一个 state 出发,经过一系列同样操作 log 的步骤,最终也必将达到一致的 state。也就是说,只要我们保证集群中所有节点的 log 一致,那么经过一系列应用(apply)后最终得到的状态机也就是一致的。
Raft 负责保证集群中所有节点 log 的一致性。
此外我们还提到过:Raft 赋予了 leader 节点更强的领导力(Strong Leader)。那么 Raft 保证 log 一致的方式就很容易理解了,即所有 log 都必须交给 leader 节点处理,并由 leader 节点复制给其它节点。
这个过程,就叫做日志复制(Log replication)。
3.2 Raft 日志复制机制解析
3.2.1 整体流程解析
一旦 leader 被票选出来,它就承担起领导整个集群的责任了,开始接收客户端请求,并将操作包装成日志,并复制到其它节点上去。
整体流程如下:
- Leader 为客户端提供服务,客户端的每个请求都包含一条即将被状态复制机执行的指令。
- Leader 把该指令作为一条新的日志附加到自身的日志集合,然后向其它节点发起附加条目请求(AppendEntries RPC),来要求它们将这条日志附加到各自本地的日志集合。
- 当这条日志已经确保被安全的复制,即大多数(N/2+1)节点都已经复制后,leader 会将该日志 apply 到它本地的状态机中,然后把操作成功的结果返回给客户端。
整个集群的日志模型可以宏观表示为下图(x ← 3 代表 x 赋值为 3):
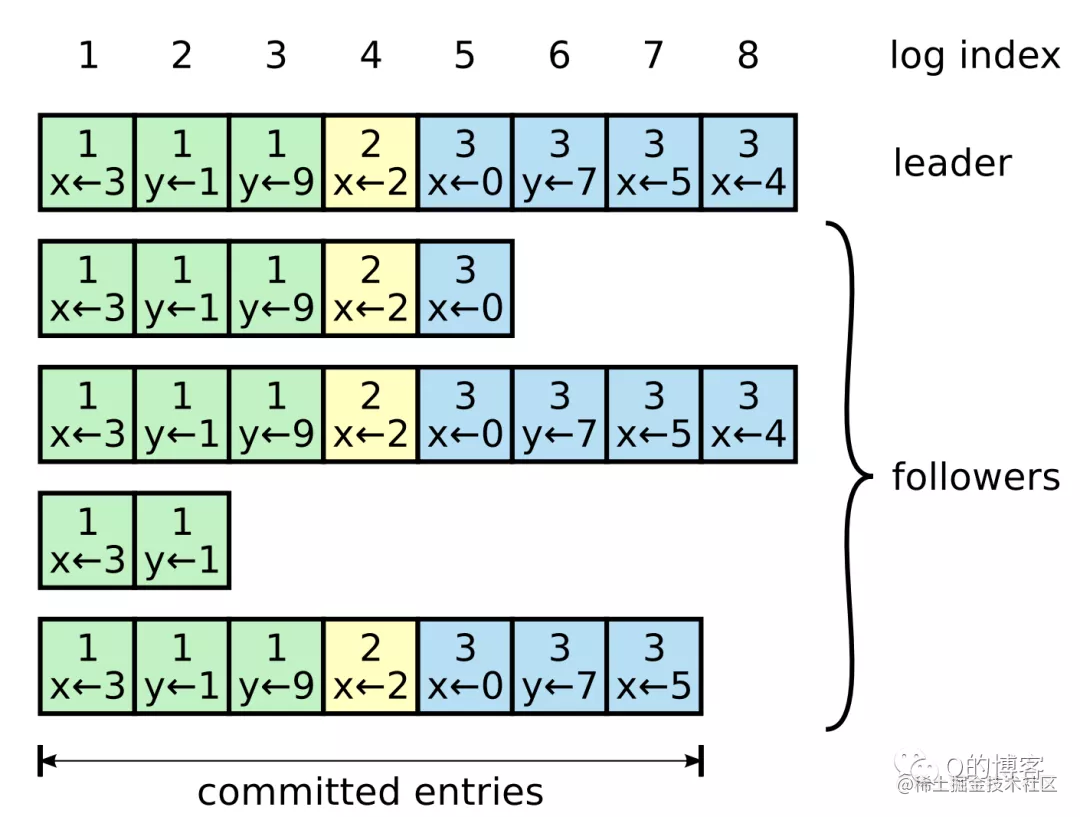
每条日志除了存储状态机的操作指令外,还会拥有一个唯一的整数索引值(log index)来表明它在日志集合中的位置。此外,每条日志还会存储一个 term 号(日志条目方块最上方的数字,相同颜色 term 号相同),该 term 表示 leader 收到这条指令时的当前任期,term 相同的 log 是由同一个 leader 在其任期内发送的。
当一条日志被 leader 节点认为可以安全的 apply 到状态机时,称这条日志是 committed(上图中的 committed entries)。那么什么样的日志可以被 commit 呢?答案是:当 leader 得知这条日志被集群过半的节点复制成功时。因此在上图中我们可以看到 (term3, index7) 这条日志以及之前的日志都是 committed,尽管有两个节点拥有的日志并不完整。
Raft 保证所有 committed 日志都已经被持久化,且“最终”一定会被状态机apply。
注:这里的“最终”用词很微妙,它表明了一个特点:Raft 保证的只是集群内日志的一致性,而我们真正期望的集群对外的状态机一致性需要我们做一些额外工作,这一点在《线性一致性与读性能优化》一章会着重介绍。
3.2.2 日志复制流程图解
我们通过 Raft 动画 来模拟常规日志复制这一过程:
如上图,S1 当选 leader,此时还没有任何日志。我们模拟客户端向 S1 发起一个请求。
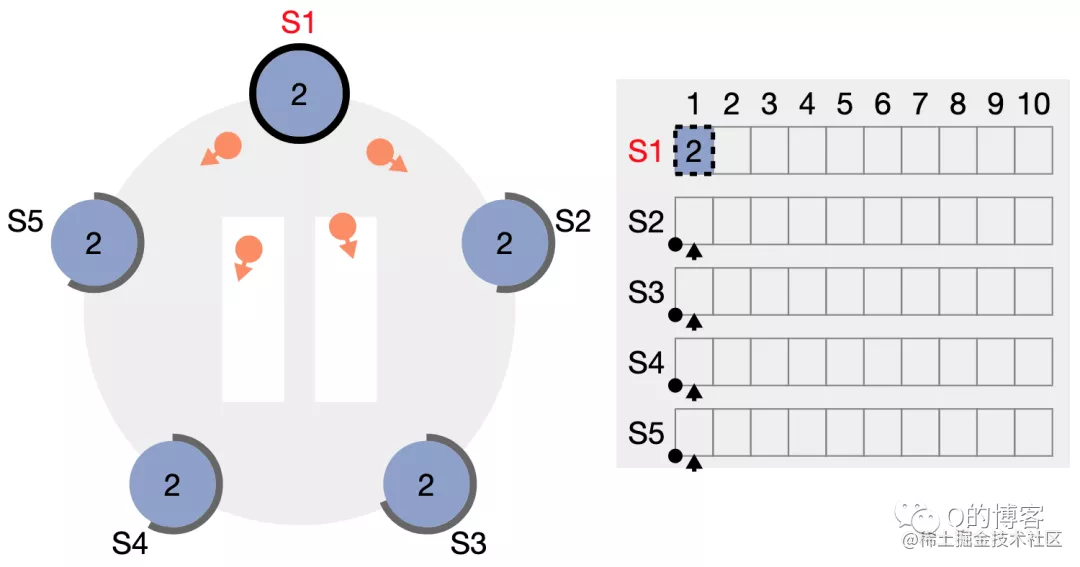
S1 收到客户端请求后新增了一条日志 (term2, index1),然后并行地向其它节点发起 AppendEntries RPC。
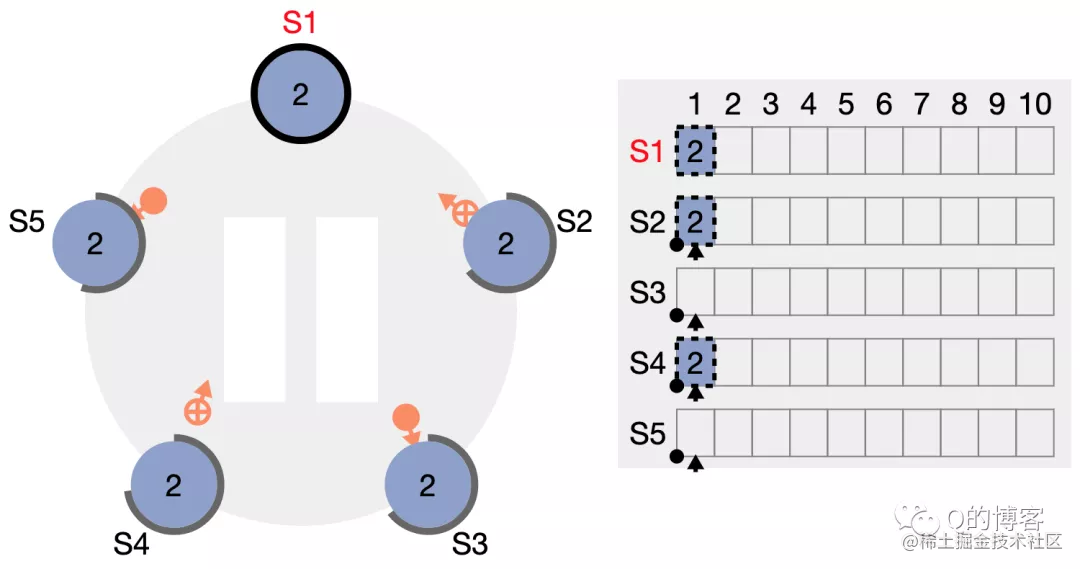
S2、S4 率先收到了请求,各自附加了该日志,并向 S1 回应响应。
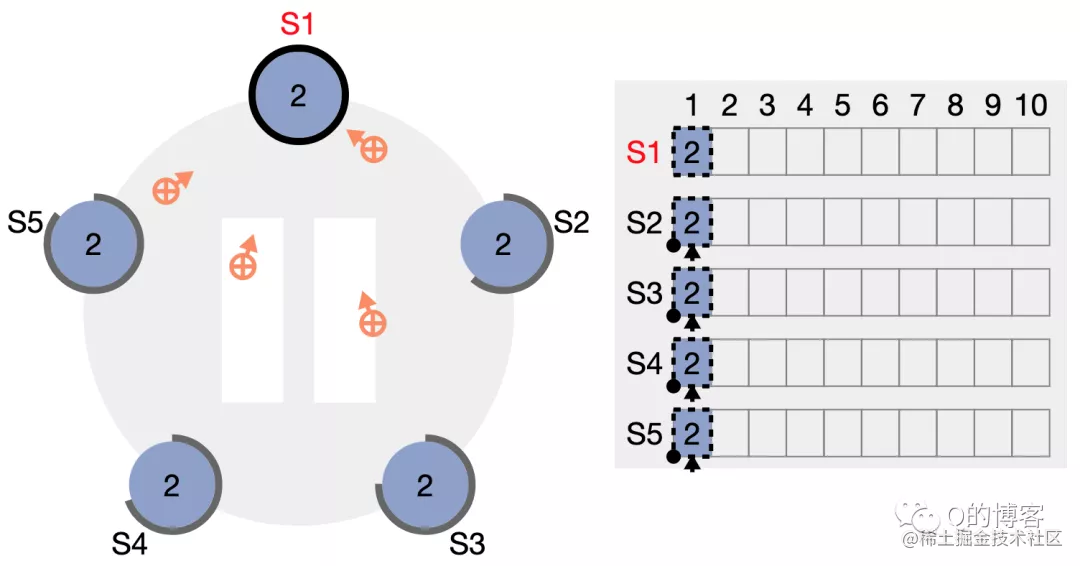
所有节点都附加了该日志,但由于 leader 尚未收到任何响应,因此暂时还不清楚该日志到底是否被成功复制。
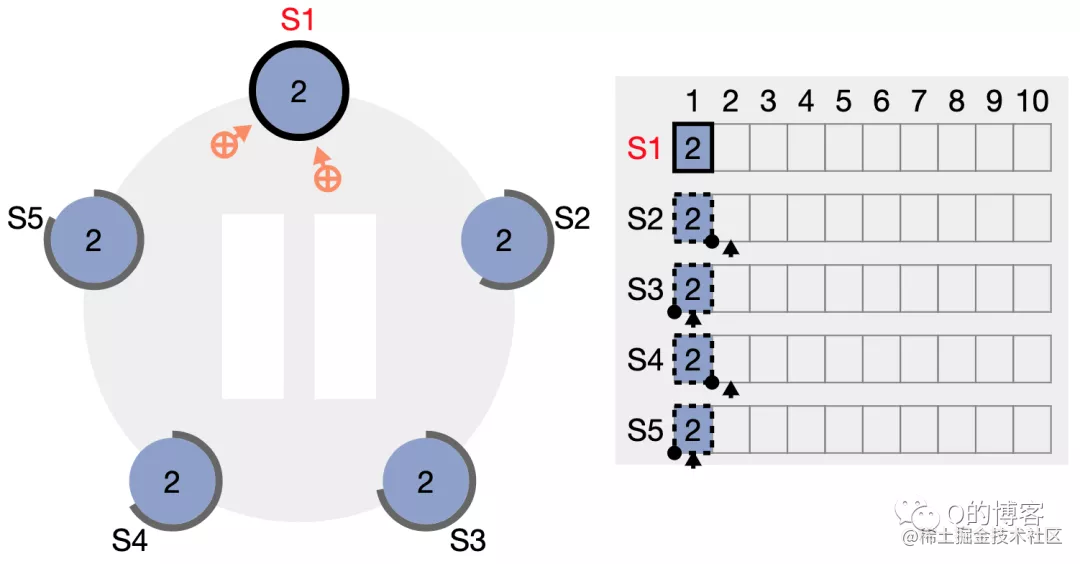
当 S1 收到2个节点的响应时,该日志条目的边框就已经变为实线,表示该日志已经安全的复制,因为在5节点集群中,2个 follower 节点加上 leader 节点自身,副本数已经确保过半,此时 S1 将响应客户端的请求。
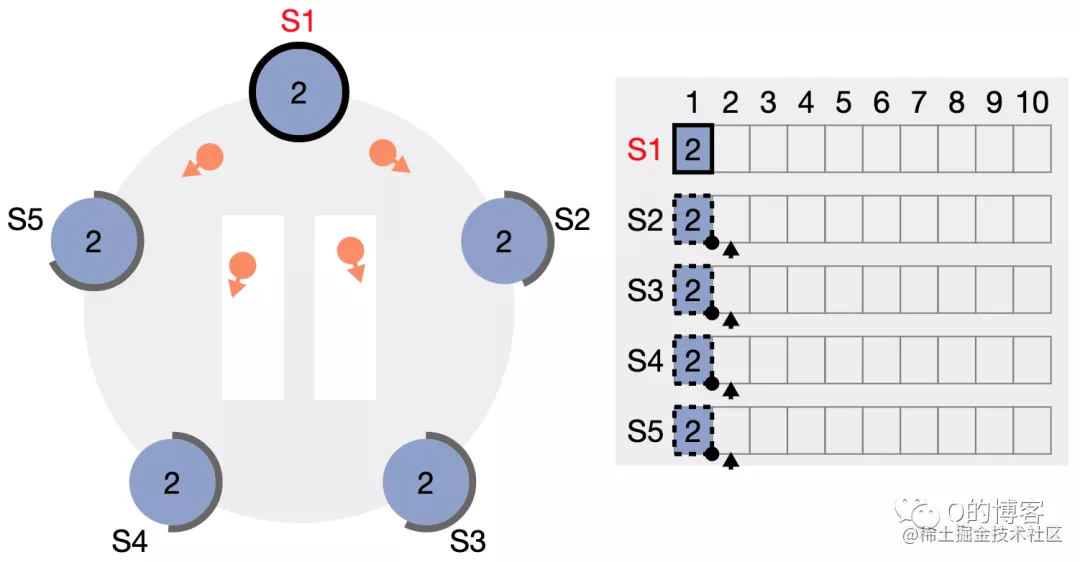
leader 后续会持续发送心跳包给 followers,心跳包中会携带当前已经安全复制(我们称之为 committed)的日志索引,此处为 (term2, index1)。
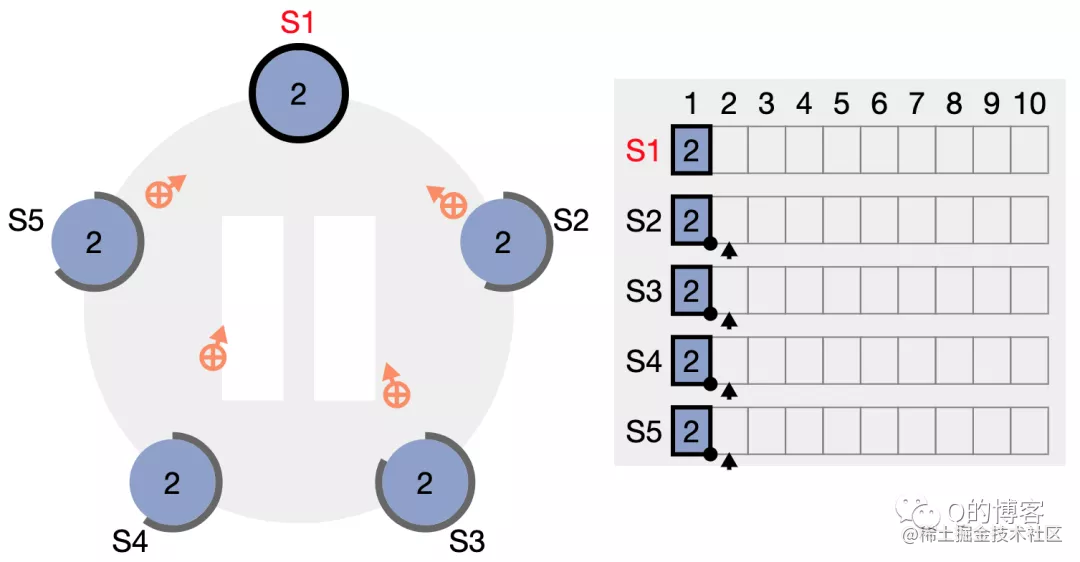
所有 follower 都通过心跳包得知 (term2, index1) 的 log 已经成功复制 (committed),因此所有节点中该日志条目的边框均变为实线。
3.2.3 对日志一致性的保证
前边我们使用了 (term2, index1) 这种方式来表示一条日志条目,这里为什么要带上 term,而不仅仅是使用 index?原因是 term 可以用来检查不同节点间日志是否存在不一致的情况,阅读下一节后会更容易理解这句话。
Raft 保证:如果不同的节点日志集合中的两个日志条目拥有相同的 term 和 index,那么它们一定存储了相同的指令。
为什么可以作出这种保证?因为 Raft 要求 leader 在一个 term 内针对同一个 index 只能创建一条日志,并且永远不会修改它。
同时 Raft 也保证:如果不同的节点日志集合中的两个日志条目拥有相同的 term 和 index,那么它们之前的所有日志条目也全部相同。
这是因为 leader 发出的 AppendEntries RPC 中会额外携带上一条日志的 (term, index),如果 follower 在本地找不到相同的 (term, index) 日志,则拒绝接收这次新的日志。
所以,只要 follower 持续正常地接收来自 leader 的日志,那么就可以通过归纳法验证上述结论。
3.2.4 可能出现的日志不一致场景
在所有节点正常工作的时候,leader 和 follower的日志总是保持一致,AppendEntries RPC 也永远不会失败。然而我们总要面对任意节点随时可能宕机的风险,如何在这种情况下继续保持集群日志的一致性才是我们真正要解决的问题。
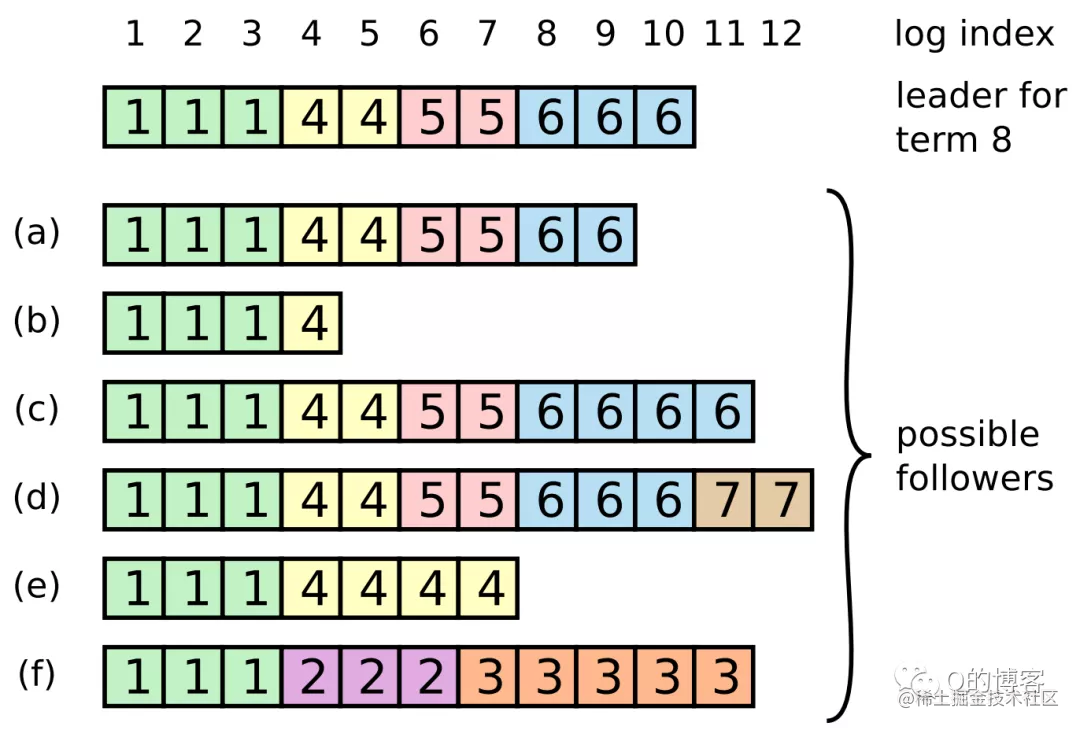
上图展示了一个 term8 的 leader 刚上任时,集群中日志可能存在的混乱情况。例如 follower 可能缺少一些日志(a ~ b),可能多了一些未提交的日志(c ~ d),也可能既缺少日志又多了一些未提交日志(e ~ f)。
注:Follower 不可能比 leader 多出一些已提交(committed)日志,这一点是通过选举上的限制来达成的,会在下一章《安全性》介绍。
我们先来尝试复现上述 a ~ f 场景,最后再讲 Raft 如何解决这种不一致问题。
场景a~b. Follower 日志落后于 leader
这种场景其实很简单,即 follower 宕机了一段时间,follower-a 从收到 (term6, index9) 后开始宕机,follower-b 从收到 (term4, index4) 后开始宕机。这里不再赘述。
场景c. Follower 日志比 leader 多 term6
当 term6 的 leader 正在将 (term6, index11) 向 follower 同步时,该 leader 发生了宕机,且此时只有 follower-c 收到了这条日志的 AppendEntries RPC。然后经过一系列的选举,term7 可能是选举超时,也可能是 leader 刚上任就宕机了,最终 term8 的 leader 上任了,成就了我们看到的场景 c。
场景d. Follower 日志比 leader 多 term7
当 term6 的 leader 将 (term6, index10) 成功 commit 后,发生了宕机。此时 term7 的 leader 走马上任,连续同步了两条日志给 follower,然而还没来得及 commit 就宕机了,随后集群选出了 term8 的 leader。
场景e. Follower 日志比 leader 少 term5 ~ 6,多 term4
当 term4 的 leader 将 (term4, index7) 同步给 follower,且将 (term4, index5) 及之前的日志成功 commit 后,发生了宕机,紧接着 follower-e 也发生了宕机。这样在 term5~7 内发生的日志同步全都被 follower-e 错过了。当 follower-e 恢复后,term8 的 leader 也刚好上任了。
场景f. Follower 日志比 leader 少 term4 ~ 6,多 term2 ~ 3
当 term2 的 leader 同步了一些日志(index4 ~ 6)给 follower 后,尚未来得及 commit 时发生了宕机,但它很快恢复过来了,又被选为了 term3 的 leader,它继续同步了一些日志(index7~11)给 follower,但同样未来得及 commit 就又发生了宕机,紧接着 follower-f 也发生了宕机,当 follower-f 醒来时,集群已经前进到 term8 了。
3.2.5 如何处理日志不一致
通过上述场景我们可以看到,真实世界的集群情况很复杂,那么 Raft 是如何应对这么多不一致场景的呢?其实方式很简单暴力,想想 Strong Leader 这个词。
Raft 强制要求 follower 必须复制 leader 的日志集合来解决不一致问题。
也就是说,follower 节点上任何与 leader 不一致的日志,都会被 leader 节点上的日志所覆盖。这并不会产生什么问题,因为某些选举上的限制,如果 follower 上的日志与 leader 不一致,那么该日志在 follower 上一定是未提交的。未提交的日志并不会应用到状态机,也不会被外部的客户端感知到。
要使得 follower 的日志集合跟自己保持完全一致,leader 必须先找到二者间最后一次达成一致的地方。因为一旦这条日志达成一致,在这之前的日志一定也都一致(回忆下前文)。这个确认操作是在 AppendEntries RPC 的一致性检查步骤完成的。
Leader 针对每个 follower 都维护一个 next index,表示下一条需要发送给该follower 的日志索引。当一个 leader 刚刚上任时,它初始化所有 next index 值为自己最后一条日志的 index+1。但凡某个 follower 的日志跟 leader 不一致,那么下次 AppendEntries RPC 的一致性检查就会失败。在被 follower 拒绝这次 Append Entries RPC 后,leader 会减少 next index 的值并进行重试。
最终一定会存在一个 next index 使得 leader 和 follower 在这之前的日志都保持一致。极端情况下 next index 为1,表示 follower 没有任何日志与 leader 一致,leader 必须从第一条日志开始同步。
针对每个 follower,一旦确定了 next index 的值,leader 便开始从该 index 同步日志,follower 会删除掉现存的不一致的日志,保留 leader 最新同步过来的。
整个集群的日志会在这个简单的机制下自动趋于一致。此外要注意,leader 从来不会覆盖或者删除自己的日志,而是强制 follower 与它保持一致。
这就要求集群票选出的 leader 一定要具备“日志的正确性”,这也就关联到了前文提到的:选举上的限制。
下一章我们将对此详细讨论。
4. 安全性及正确性
前面的章节我们讲述了 Raft 算法是如何选主和复制日志的,然而到目前为止我们描述的这套机制还不能保证每个节点的状态机会严格按照相同的顺序 apply 日志。想象以下场景:
- Leader 将一些日志复制到了大多数节点上,进行 commit 后发生了宕机。
- 某个 follower 并没有被复制到这些日志,但它参与选举并当选了下一任 leader。
- 新的 leader 又同步并 commit 了一些日志,这些日志覆盖掉了其它节点上的上一任 committed 日志。
- 各个节点的状态机可能 apply 了不同的日志序列,出现了不一致的情况。
因此我们需要对“选主+日志复制”这套机制加上一些额外的限制,来保证状态机的安全性,也就是 Raft 算法的正确性。
4.1 对选举的限制
我们再来分析下前文所述的 committed 日志被覆盖的场景,根本问题其实发生在第2步。Candidate 必须有足够的资格才能当选集群 leader,否则它就会给集群带来不可预料的错误。Candidate 是否具备这个资格可以在选举时添加一个小小的条件来判断,即:
每个 candidate 必须在 RequestVote RPC 中携带自己本地日志的最新 (term, index),如果 follower 发现这个 candidate 的日志还没有自己的新,则拒绝投票给该 candidate。
Candidate 想要赢得选举成为 leader,必须得到集群大多数节点的投票,那么它的日志就一定至少不落后于大多数节点。又因为一条日志只有复制到了大多数节点才能被 commit,因此能赢得选举的 candidate 一定拥有所有 committed 日志。
因此前一篇文章我们才会断定地说:Follower 不可能比 leader 多出一些 committed 日志。
比较两个 (term, index) 的逻辑非常简单:如果 term 不同 term 更大的日志更新,否则 index 大的日志更新。
4.2 对提交的限制
除了对选举增加一点限制外,我们还需对 commit 行为增加一点限制,来完成我们 Raft 算法核心部分的最后一块拼图。
回忆下什么是 commit:
当 leader 得知某条日志被集群过半的节点复制成功时,就可以进行 commit,committed 日志一定最终会被状态机 apply。
所谓 commit 其实就是对日志简单进行一个标记,表明其可以被 apply 到状态机,并针对相应的客户端请求进行响应。
然而 leader 并不能在任何时候都随意 commit 旧任期留下的日志,即使它已经被复制到了大多数节点。Raft 论文给出了一个经典场景:
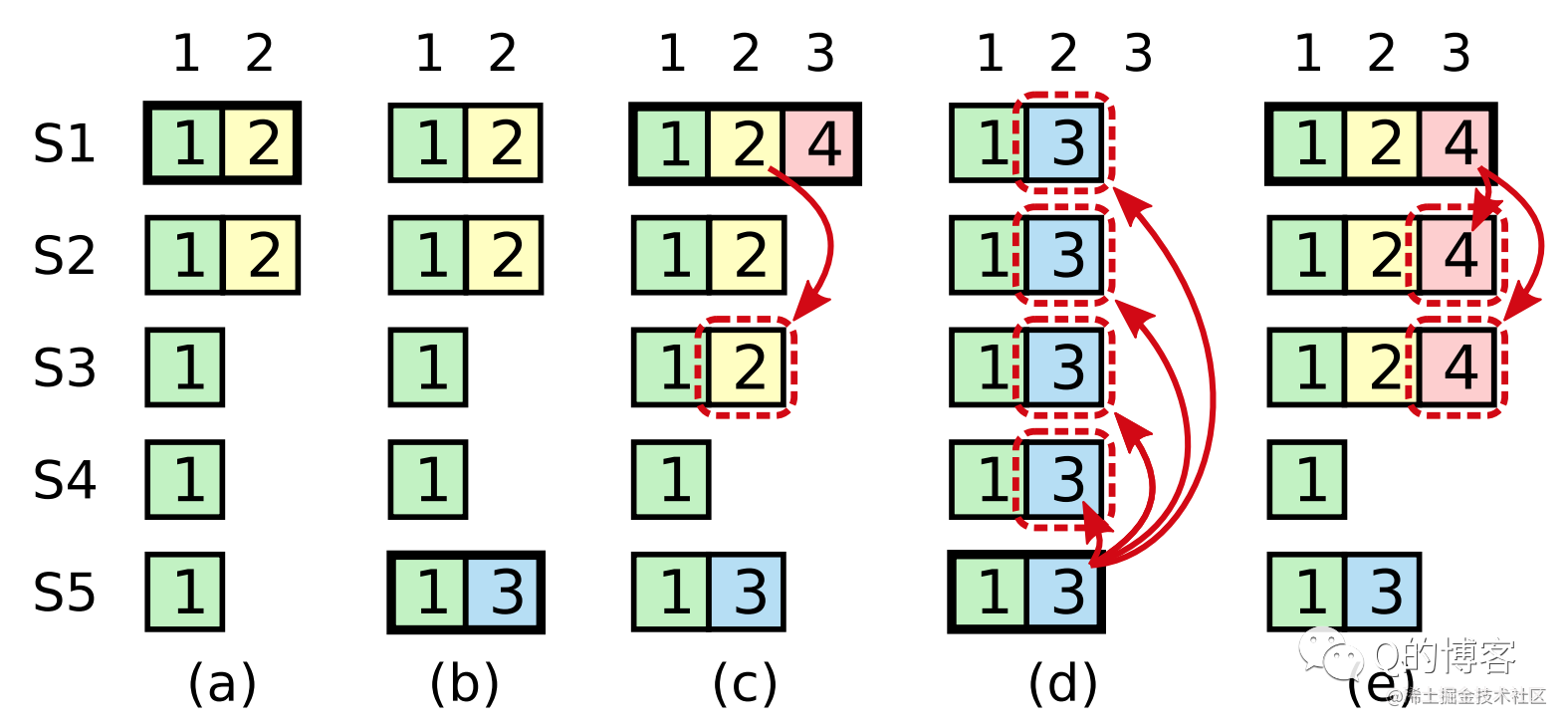
上图从左到右按时间顺序模拟了问题场景。
阶段a:S1 是 leader,收到请求后将 (term2, index2) 只复制给了 S2,尚未复制给 S3 ~ S5。
阶段b:S1 宕机,S5 当选 term3 的 leader(S3、S4、S5 三票),收到请求后保存了 (term3, index2),尚未复制给任何节点。
阶段c:S5 宕机,S1 恢复,S1 重新当选 term4 的 leader,继续将 (term2, index2) 复制给了 S3,已经满足大多数节点,我们将其 commit。
阶段d:S1 又宕机,S5 恢复,S5 重新当选 leader(S2、S3、S4 三票),将 (term3, inde2) 复制给了所有节点并 commit。注意,此时发生了致命错误,已经 committed 的 (term2, index2) 被 (term3, index2) 覆盖了。
为了避免这种错误,我们需要添加一个额外的限制:
Leader 只允许 commit 包含当前 term 的日志。
针对上述场景,问题发生在阶段c,即使作为 term4 leader 的 S1 将 (term2, index2) 复制给了大多数节点,它也不能直接将其 commit,而是必须等待 term4 的日志到来并成功复制后,一并进行 commit。
阶段e:在添加了这个限制后,要么 (term2, index2) 始终没有被 commit,这样 S5 在阶段d将其覆盖就是安全的;要么 (term2, index2) 同 (term4, index3) 一起被 commit,这样 S5 根本就无法当选 leader,因为大多数节点的日志都比它新,也就不存在前边的问题了。
以上便是对算法增加的两个小限制,它们对确保状态机的安全性起到了至关重要的作用。
至此我们对 Raft 算法的核心部分,已经介绍完毕。下一章我们会介绍两个同样描述于论文内的辅助技术:集群成员变更和日志压缩,它们都是在 Raft 工程实践中必不可少的部分。
5. 集群成员变更与日志压缩
尽管我们已经通过前几章了解了 Raft 算法的核心部分,但相较于算法理论来说,在工程实践中仍有一些现实问题需要我们去面对。Raft 非常贴心的在论文中给出了两个常见问题的解决方案,它们分别是:
- 集群成员变更:如何安全地改变集群的节点成员。
- 日志压缩:如何解决日志集合无限制增长带来的问题。
本文我们将分别讲解这两种技术。
5.1 集群成员变更
在前文的理论描述中我们都假设了集群成员是不变的,然而在实践中有时会需要替换宕机机器或者改变复制级别(即增减节点)。一种最简单暴力达成目的的方式就是:停止集群、改变成员、启动集群。这种方式在执行时会导致集群整体不可用,此外还存在手工操作带来的风险。
为了避免这样的问题,Raft 论文中给出了一种无需停机的、自动化的改变集群成员的方式,其实本质上还是利用了 Raft 的核心算法,将集群成员配置作为一个特殊日志从 leader 节点同步到其它节点去。
5.1.1 直接切换集群成员配置
先说结论:所有将集群从旧配置直接完全切换到新配置的方案都是不安全的。
因此我们不能想当然的将新配置直接作为日志同步给集群并 apply。因为我们不可能让集群中的全部节点在“同一时刻”原子地切换其集群成员配置,所以在切换期间不同的节点看到的集群视图可能存在不同,最终可能导致集群存在多个 leader。
为了理解上述结论,我们来看一个实际出现问题的场景,下图对其进行了展现。
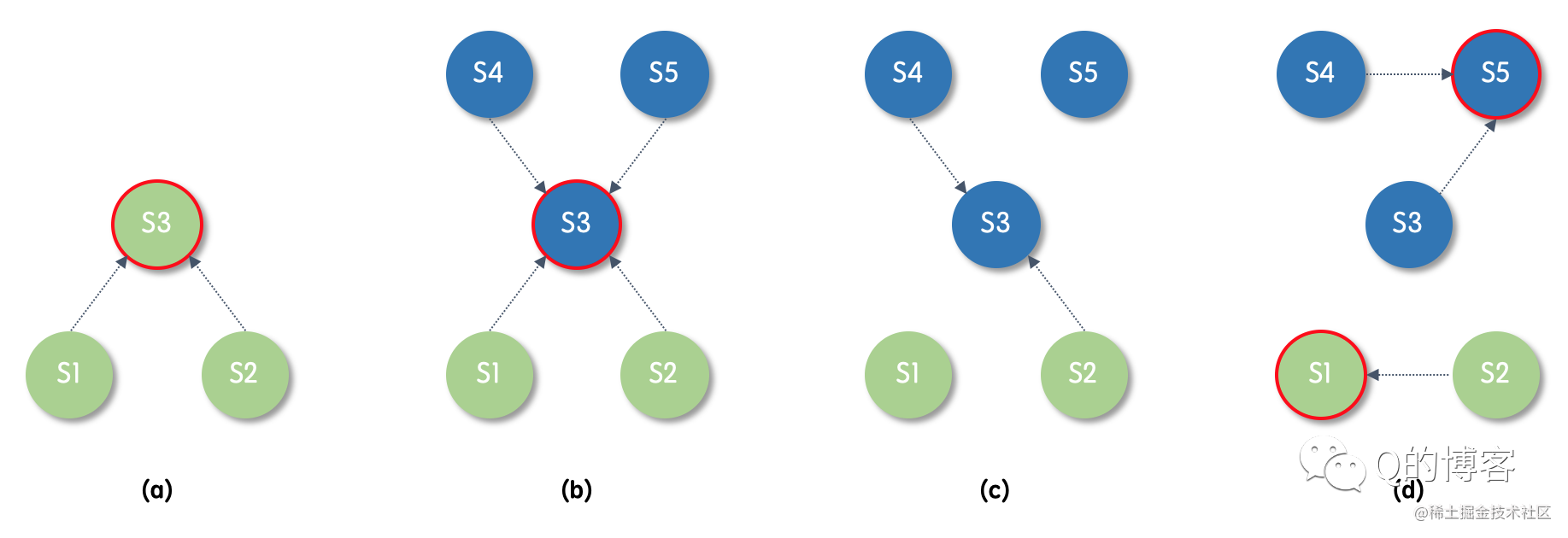 图5-1
图5-1
阶段a. 集群存在 S1 ~ S3 三个节点,我们将该成员配置表示为 C-old,绿色表示该节点当前视图(成员配置)为 C-old,其中红边的 S3 为 leader。
阶段b. 集群新增了 S4、S5 两个节点,该变更从 leader 写入,我们将 S1 ~ S5 的五节点新成员配置表示为 C-new,蓝色表示该节点当前视图为 C-new。
阶段c. 假设 S3 短暂宕机触发了 S1 与 S5 的超时选主。
阶段d. S1 向 S2、S3 拉票,S5 向其它全部四个节点拉票。由于 S2 的日志并没有比 S1 更新,因此 S2 可能会将选票投给 S1,S1 两票当选(因为 S1 认为集群只有三个节点)。而 S5 肯定会得到 S3、S4 的选票,因为 S1 感知不到 S4,没有向它发送 RequestVote RPC,并且 S1 的日志落后于 S3,S3 也一定不会投给 S1,结果 S5 三票当选。最终集群出现了多个主节点的致命错误,也就是所谓的脑裂。
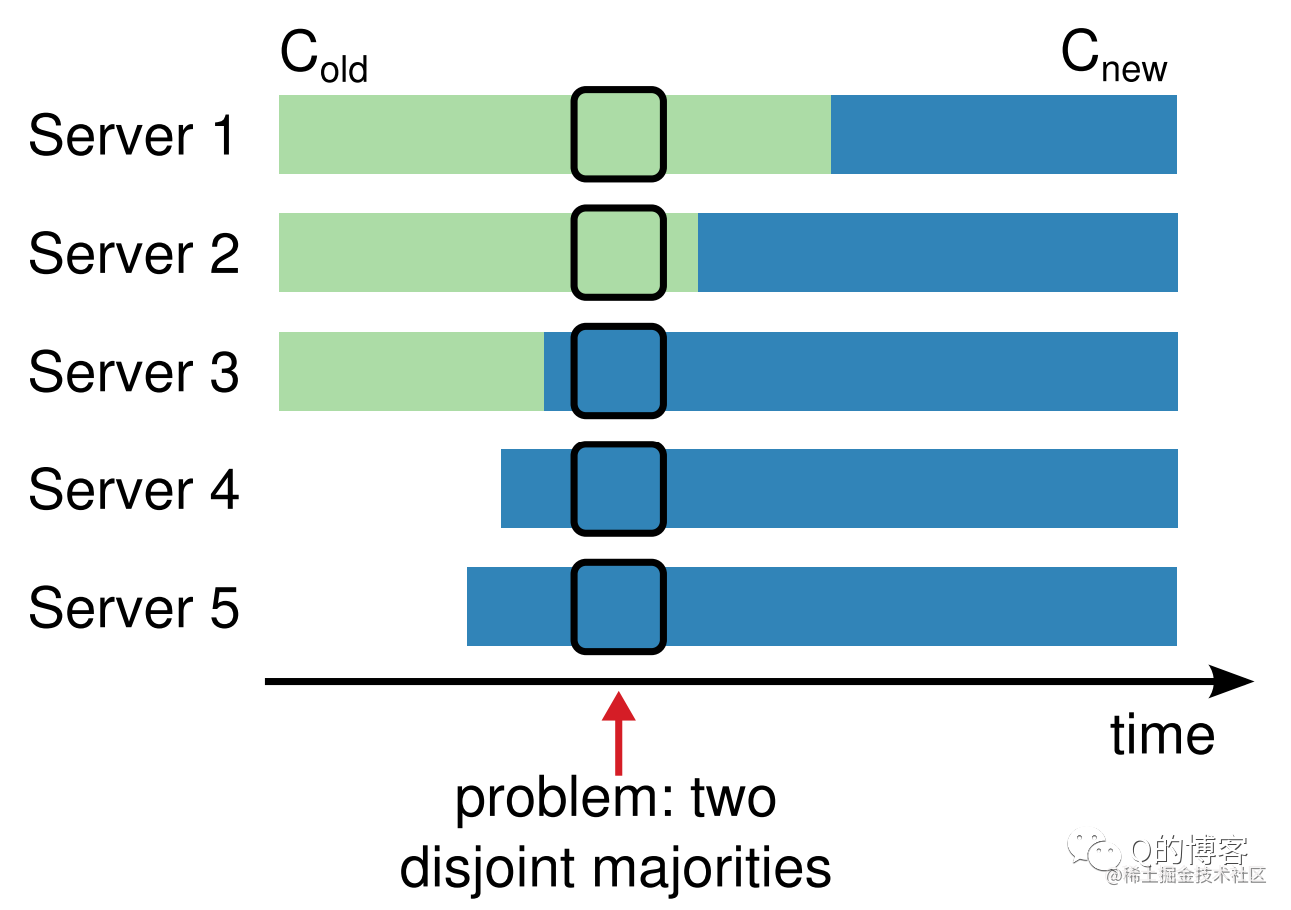 图5-2
图5-2
上图来自论文,用不同的形式展现了和图5-1相同的问题。颜色代表的含义与图5-1是一致的,在 problem: two disjoint majorities 所指的时间点,集群可能会出现两个 leader。
但是,多主问题并不是在任何新老节点同时选举时都一定可能出现的,社区一些文章在举多主的例子时可能存在错误,下面是一个案例(笔者学习 Raft 协议也从这篇文章中受益匪浅,应该是作者行文时忽略了。文章很赞,建议大家参考学习):
来源:zhuanlan.zhihu.com/p/27207160
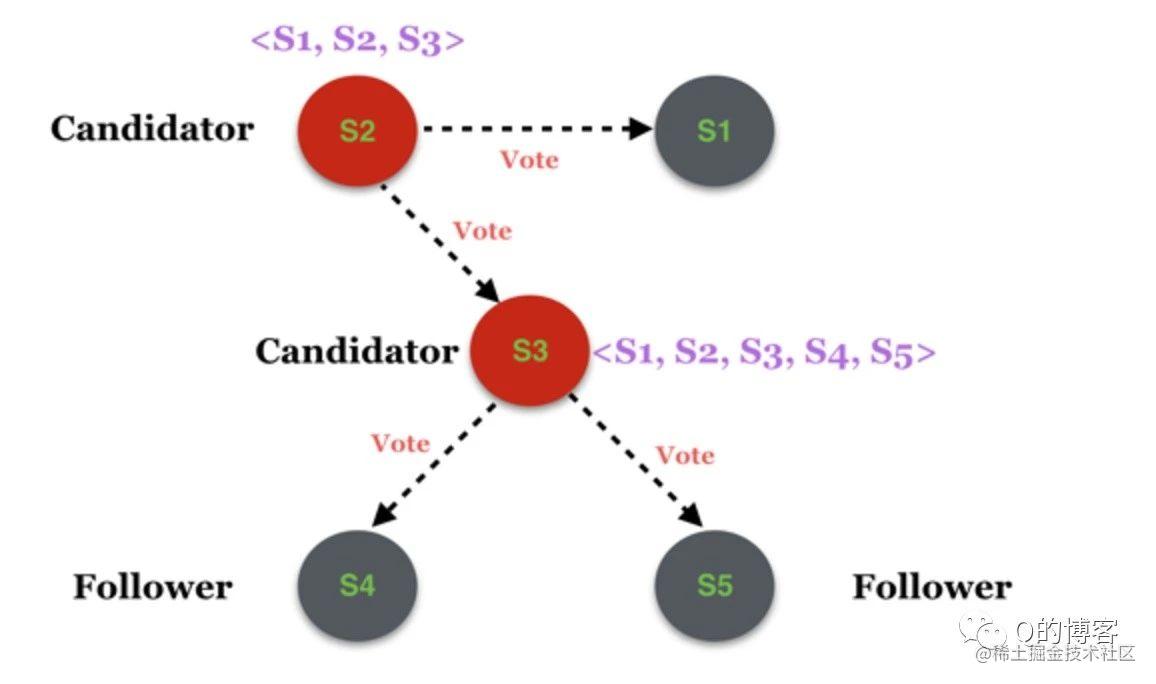 图5-3
图5-3
该假想场景类似图5-1的阶段d,模拟过程如下:
- S1 为集群原 leader,集群新增 S4、S5,该配置被推给了 S3,S2 尚未收到。
- 此时 S1 发生短暂宕机,S2、S3 分别触发选主。
- 最终 S2 获得了 S1 和自己的选票,S3 获得了 S4、S5 和自己的选票,集群出现两个 leader。
图5-3过程看起来好像和图5-1没有什么大的不同,只是参与选主的节点存在区别,然而事实是图5-3的情况是不可能出现的。
注意:Raft 论文中传递集群变更信息也是通过日志追加实现的,所以也受到选主的限制。很多读者对选主限制中比较的日志是否必须是 committed 产生疑惑,回看下在《安全性》一文中的描述:
每个 candidate 必须在 RequestVote RPC 中携带自己本地日志的最新 (term, index),如果 follower 发现这个 candidate 的日志还没有自己的新,则拒绝投票给该 candidate。
这里再帮大家明确下,论文里确实间接表明了,选主时比较的日志是不要求 committed 的,只需比较本地的最新日志就行!
回到图5-3,不可能出现的原因在于,S1 作为原 leader 已经第一个保存了新配置的日志,而 S2 尚未被同步这条日志,根据上一章《安全性》我们讲到的选主限制,S1 不可能将选票投给 S2,因此 S2 不可能成为 leader。
5.1.2 两阶段切换集群成员配置
Raft 使用一种两阶段方法平滑切换集群成员配置来避免遇到前一节描述的问题,具体流程如下:
阶段一
- 客户端将 C-new 发送给 leader,leader 将 C-old 与 C-new 取并集并立即apply,我们表示为 C-old,new。
- Leader 将 C-old,new 包装为日志同步给其它节点。
- Follower 收到 C-old,new 后立即 apply,当 **C-old,new 的大多数节点(即 C-old 的大多数节点和 C-new 的大多数节点)**都切换后,leader 将该日志 commit。
阶段二
- Leader 接着将 C-new 包装为日志同步给其它节点。
- Follower 收到 C-new 后立即 apply,如果此时发现自己不在 C-new 列表,则主动退出集群。
- Leader 确认 C-new 的大多数节点都切换成功后,给客户端发送执行成功的响应。
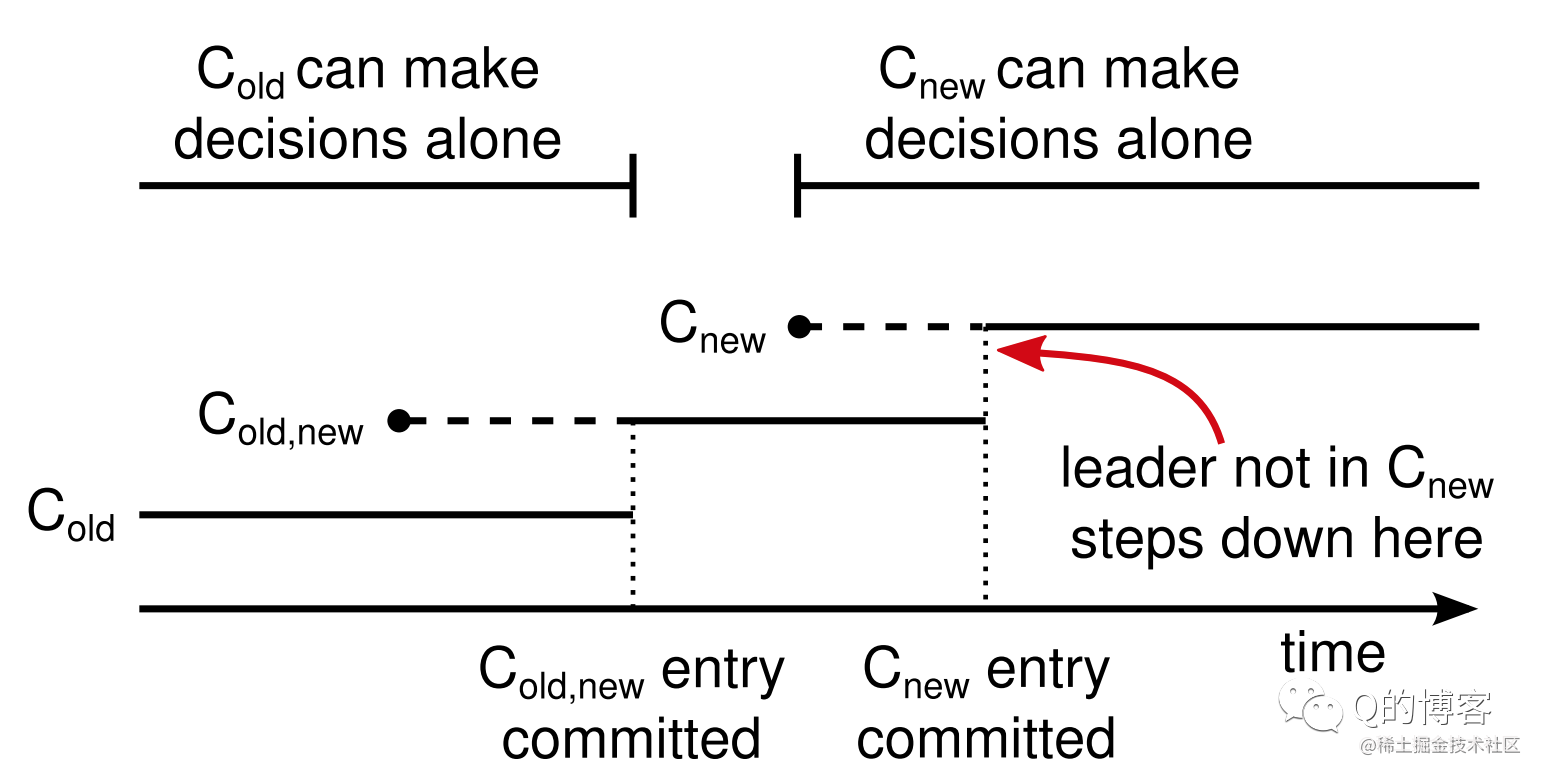
上图展示了该流程的时间线。虚线表示已经创建但尚未 commit 的成员配置日志,实线表示 committed 的成员配置日志。
为什么该方案可以保证不会出现多个 leader?我们来按流程逐阶段分析。
阶段1. C-old,new 尚未 commit
该阶段所有节点的配置要么是 C-old,要么是 C-old,new,但无论是二者哪种,只要原 leader 发生宕机,新 leader 都必须得到大多数 C-old 集合内节点的投票。
以图5-1场景为例,S5 在阶段d根本没有机会成为 leader,因为 C-old 中只有 S3 给它投票了,不满足大多数。
阶段2. C-old,new 已经 commit,C-new 尚未下发
该阶段 C-old,new 已经 commit,可以确保已经被 C-old,new 的大多数节点(再次强调:C-old 的大多数节点和 C-new 的大多数节点)复制。
因此当 leader 宕机时,新选出的 leader 一定是已经拥有 C-old,new 的节点,不可能出现两个 leader。
阶段3. C-new 已经下发但尚未 commit
该阶段集群中可能有三种节点 C-old、C-old,new、C-new,但由于已经经历了阶段2,因此 C-old 节点不可能再成为 leader。而无论是 C-old,new 还是 C-new 节点发起选举,都需要经过大多数 C-new 节点的同意,因此也不可能出现两个 leader。
阶段4. C-new 已经 commit
该阶段 C-new 已经被 commit,因此只有 C-new 节点可以得到大多数选票成为 leader。此时集群已经安全地完成了这轮变更,可以继续开启下一轮变更了。
以上便是对该两阶段方法可行性的分步验证,Raft 论文将该方法称之为共同一致(Joint Consensus)。
关于集群成员变更另一篇更详细的论文还给出了其它方法,简单来说就是论证一次只变更一个节点的的正确性,并给出解决可用性问题的优化方案。感兴趣的同学可以参考:《Consensus: Bridging Theory and Practice》。
5.2 日志压缩
我们知道 Raft 核心算法维护了日志的一致性,通过 apply 日志我们也就得到了一致的状态机,客户端的操作命令会被包装成日志交给 Raft 处理。然而在实际系统中,客户端操作是连绵不断的,但日志却不能无限增长,首先它会占用很高的存储空间,其次每次系统重启时都需要完整回放一遍所有日志才能得到最新的状态机。
因此 Raft 提供了一种机制去清除日志里积累的陈旧信息,叫做日志压缩。
快照(Snapshot)是一种常用的、简单的日志压缩方式,ZooKeeper、Chubby 等系统都在用。简单来说,就是将某一时刻系统的状态 dump 下来并落地存储,这样该时刻之前的所有日志就都可以丢弃了。所以大家对“压缩”一词不要产生错误理解,我们并没有办法将状态机快照“解压缩”回日志序列。
注意,在 Raft 中我们只能为 committed 日志做 snapshot,因为只有 committed 日志才是确保最终会应用到状态机的。
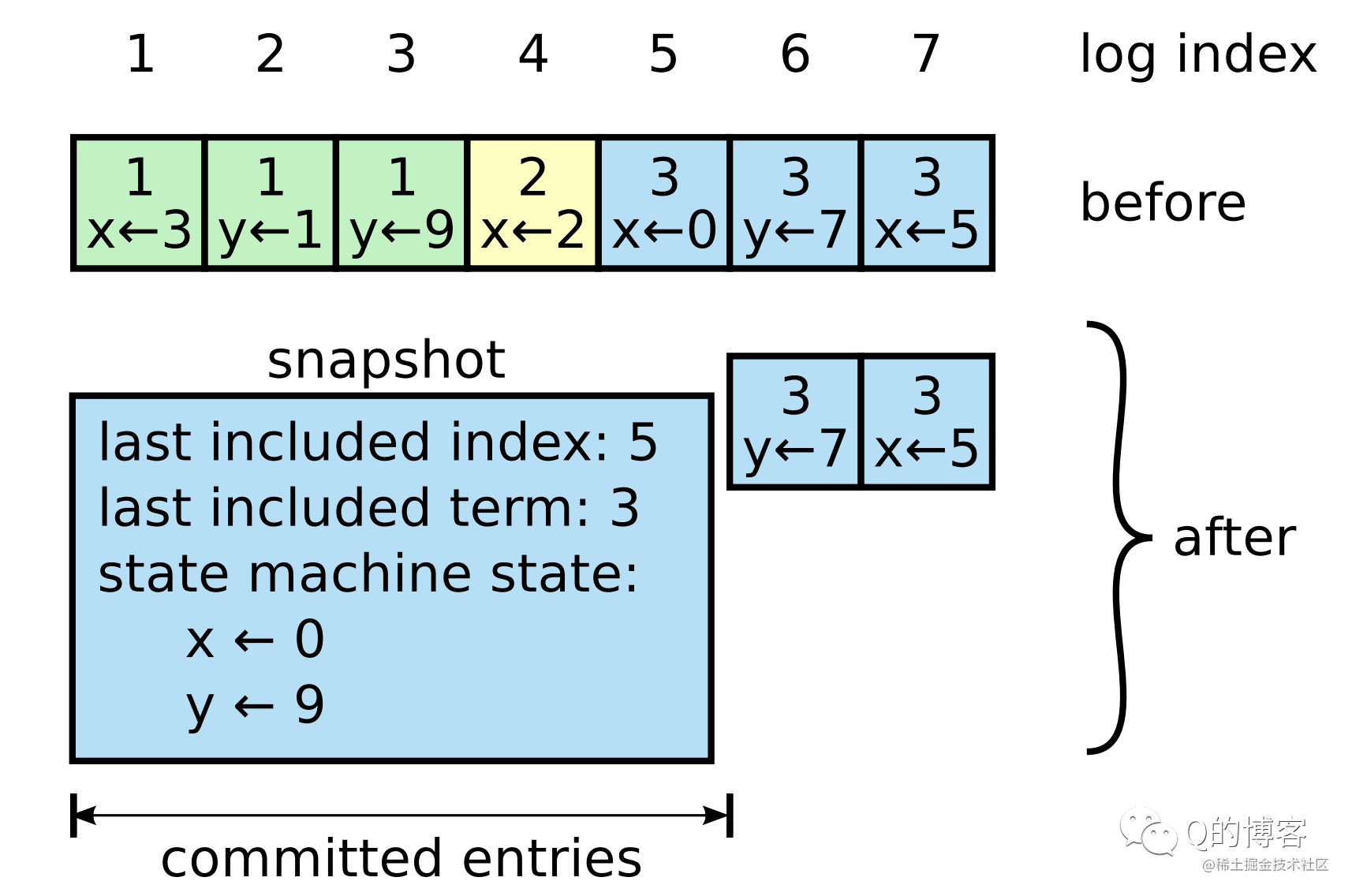
上图展示了一个节点用快照替换了 (term1, index1) ~ (term3, index5) 的日志。
快照一般包含以下内容:
- 日志的元数据:最后一条被该快照 apply 的日志 term 及 index
- 状态机:前边全部日志 apply 后最终得到的状态机
当 leader 需要给某个 follower 同步一些旧日志,但这些日志已经被 leader 做了快照并删除掉了时,leader 就需要把该快照发送给 follower。
同样,当集群中有新节点加入,或者某个节点宕机太久落后了太多日志时,leader 也可以直接发送快照,大量节约日志传输和回放时间。
同步快照使用一个新的 RPC 方法,叫做 InstallSnapshot RPC。
至此我们已经将 Raft 论文中的内容基本讲解完毕了。《In Search of an Understandable Consensus Algorithm (Extended Version)》 毕竟只有18页,更加侧重于理论描述而非工程实践。如果你想深入学习 Raft,或自己动手写一个靠谱的 Raft 实现,《Consensus: Bridging Theory and Practice》 是你参考的不二之选。
接下来我们将额外讨论一下关于线性一致性和 Raft 读性能优化的内容。
6. 线性一致性与读性能优化
6.1 什么是线性一致性?
在该系列首篇《基本概念》中我们提到过:在分布式系统中,为了消除单点提高系统可用性,通常会使用副本来进行容错,但这会带来另一个问题,即如何保证多个副本之间的一致性。
什么是一致性?所谓一致性有很多种模型,不同的模型都是用来评判一个并发系统正确与否的不同程度的标准。而我们今天要讨论的是强一致性(Strong Consistency)模型,也就是线性一致性(Linearizability),我们经常听到的 CAP 理论中的 C 指的就是它。
其实我们在第一篇就已经简要描述过何为线性一致性:
所谓的强一致性(线性一致性)并不是指集群中所有节点在任一时刻的状态必须完全一致,而是指一个目标,即让一个分布式系统看起来只有一个数据副本,并且读写操作都是原子的,这样应用层就可以忽略系统底层多个数据副本间的同步问题。也就是说,我们可以将一个强一致性分布式系统当成一个整体,一旦某个客户端成功的执行了写操作,那么所有客户端都一定能读出刚刚写入的值。即使发生网络分区故障,或者少部分节点发生异常,整个集群依然能够像单机一样提供服务。
“像单机一样提供服务”从感官上描述了一个线性一致性系统应该具备的特性,那么我们该如何判断一个系统是否具备线性一致性呢?通俗来说就是不能读到旧(stale)数据,但具体分为两种情况:
- 对于调用时间存在重叠(并发)的请求,生效顺序可以任意确定。
- 对于调用时间存在先后关系(偏序)的请求,后一个请求不能违背前一个请求确定的结果。
只要根据上述两条规则即可判断一个系统是否具备线性一致性。下面我们来看一个非线性一致性系统的例子。
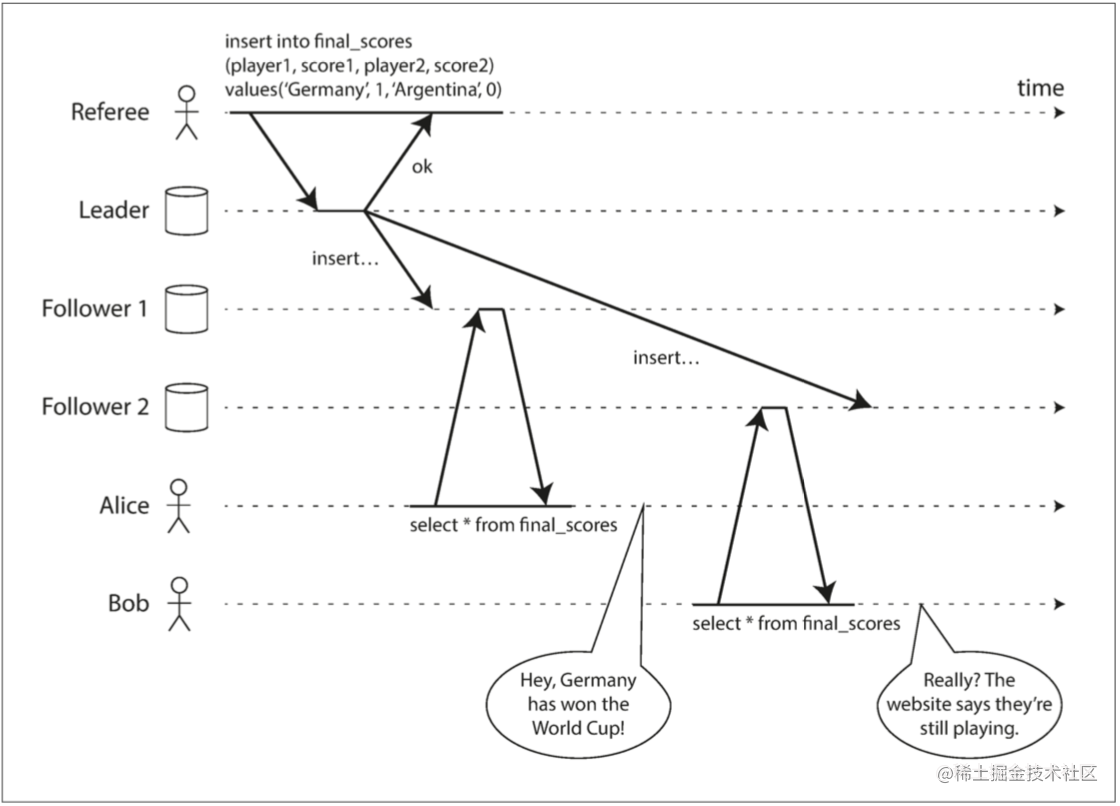
本节例图均来自《Designing Data-Intensive Application》,作者 Martin Kleppmann
如上图所示,裁判将世界杯的比赛结果写入了主库,Alice 和 Bob 所浏览的页面分别从两个不同的从库读取,但由于存在主从同步延迟,Follower 2 的本次同步延迟高于 Follower 1,最终导致 Bob 听到了 Alice 的惊呼后刷新页面看到的仍然是比赛进行中。
虽然线性一致性的基本思想很简单,只是要求分布式系统看起来只有一个数据副本,但在实际中还是有很多需要关注的点,我们继续看几个例子。
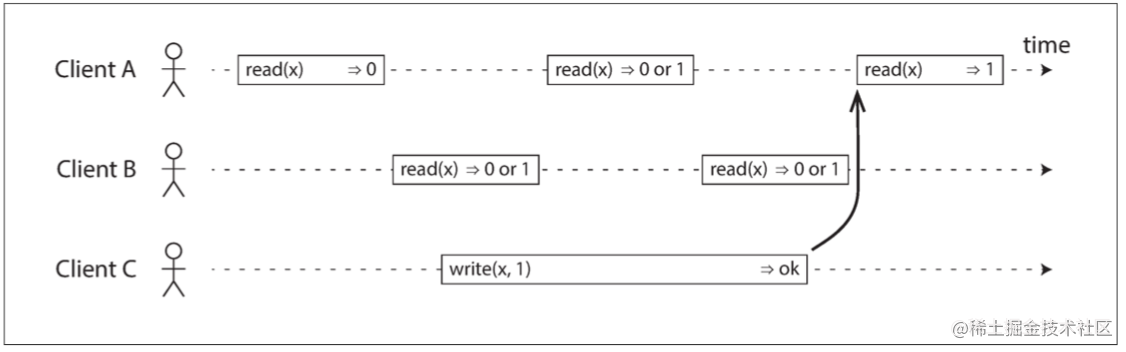
上图从客户端的外部视角展示了多个用户同时请求读写一个系统的场景,每条柱形都是用户发起的一个请求,左端是请求发起的时刻,右端是收到响应的时刻。由于网络延迟和系统处理时间并不固定,所以柱形长度并不相同。
x 最初的值为 0,Client C 在某个时间段将 x 写为 1。- Client A 第一个读操作位于 Client C 的写操作之前,因此必须读到原始值
0。
- Client A 最后一个读操作位于 Client C 的写操作之后,如果系统是线性一致的,那么必须读到新值
1。
- 其它与写操作重叠的所有读操作,既可能返回
0,也可能返回 1,因为我们并不清楚写操作在哪个时间段内哪个精确的点生效,这种情况下读写是并发的。
仅仅是这样的话,仍然不能说这个系统满足线性一致。假设 Client B 的第一次读取返回了 1,如果 Client A 的第二次读取返回了 0,那么这种场景并不破坏上述规则,但这个系统仍不满足线性一致,因为客户端在写操作执行期间看到 x 的值在新旧之间来回翻转,这并不符合我们期望的“看起来只有一个数据副本”的要求。
所以我们需要额外添加一个约束,如下图所示。
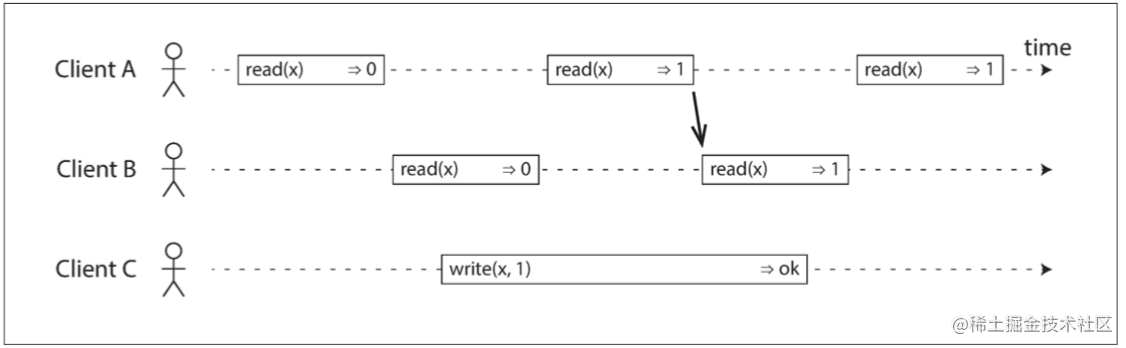
在任何一个客户端的读取返回新值后,所有客户端的后续读取也必须返回新值,这样系统便满足线性一致了。
我们最后来看一个更复杂的例子,继续细化这个时序图。
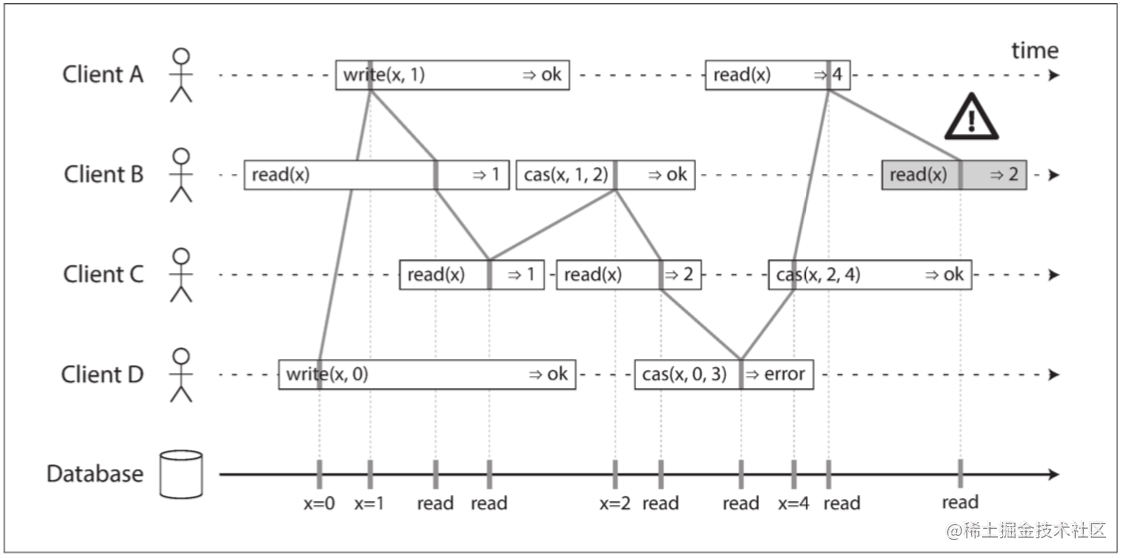
如上图所示,每个读写操作在某个特定的时间点都是原子性的生效,我们在柱形中用竖线标记出生效的时间点,将这些标记按时间顺序连接起来。那么线性一致的要求就是:连线总是按照时间顺序向右移动,而不会向左回退。所以这个连线结果必定是一个有效的寄存器读写序列:任何客户端的每次读取都必须返回该条目最近一次写入的值。
线性一致性并非限定在分布式环境下,在单机单核系统中可以简单理解为“寄存器”的特性。
Client B 的最后一次读操作并不满足线性一致,因为在连线向右移动的前提下,它读到的值是错误的(因为Client A 已经读到了由 Client C 写入的 4)。此外这张图里还有一些值得指出的细节点,可以解开很多我们在使用线性一致系统时容易产生的误解:
- Client B 的首个读请求在 Client D 的首个写请求和 Client A 的首个写请求之前发起,但最终读到的却是最后由 Client A 写成功之后的结果。
- Client A 尚未收到首个写请求成功的响应时,Client B 就读到了 Client A 写入的值。
上述现象在线性一致的语义下都是合理的。
所以线性一致性(Linearizability)除了叫强一致性(Strong Consistency)外,还叫做原子一致性(Atomic Consistency)、立即一致性(Immediate Consistency)或外部一致性(External Consistency),这些名字看起来都是比较贴切的。
6.2 Raft 线性一致性读
在了解了什么是线性一致性之后,我们将其与 Raft 结合来探讨。首先需要明确一个问题,使用了 Raft 的系统都是线性一致的吗?不是的,Raft 只是提供了一个基础,要实现整个系统的线性一致还需要做一些额外的工作。
假设我们期望基于 Raft 实现一个线性一致的分布式 kv 系统,让我们从最朴素的方案开始,指出每种方案存在的问题,最终使整个系统满足线性一致性。
6.2.1 写主读从缺陷分析
写操作并不是我们关注的重点,如果你稍微看了一些理论部分就应该知道,所有写操作都要作为提案从 leader 节点发起,当然所有的写命令都应该简单交给 leader 处理。真正关键的点在于读操作的处理方式,这涉及到整个系统关于一致性方面的取舍。
在该方案中我们假设读操作直接简单地向 follower 发起,那么由于 Raft 的 Quorum 机制(大部分节点成功即可),针对某个提案在某一时间段内,集群可能会有以下两种状态:
- 某次写操作的日志尚未被复制到一少部分 follower,但 leader 已经将其 commit。
- 某次写操作的日志已经被同步到所有 follower,但 leader 将其 commit 后,心跳包尚未通知到一部分 follower。
以上每个场景客户端都可能读到过时的数据,整个系统显然是不满足线性一致的。
6.2.2 写主读主缺陷分析
在该方案中我们限定,所有的读操作也必须经由 leader 节点处理,读写都经过 leader 难道还不能满足线性一致?是的!! 并且该方案存在不止一个问题!!
问题一:状态机落后于 committed log 导致脏读
回想一下前文讲过的,我们在解释什么是 commit 时提到了写操作什么时候可以响应客户端:
所谓 commit 其实就是对日志简单进行一个标记,表明其可以被 apply 到状态机,并针对相应的客户端请求进行响应。
也就是说一个提案只要被 leader commit 就可以响应客户端了,Raft 并没有限定提案结果在返回给客户端前必须先应用到状态机。所以从客户端视角当我们的某个写操作执行成功后,下一次读操作可能还是会读到旧值。
这个问题的解决方式很简单,在 leader 收到读命令时我们只需记录下当前的 commit index,当 apply index 追上该 commit index 时,即可将状态机中的内容响应给客户端。
问题二:网络分区导致脏读
假设集群发生网络分区,旧 leader 位于少数派分区中,而且此刻旧 leader 刚好还未发现自己已经失去了领导权,当多数派分区选出了新的 leader 并开始进行后续写操作时,连接到旧 leader 的客户端可能就会读到旧值了。
因此,仅仅是直接读 leader 状态机的话,系统仍然不满足线性一致性。
6.2.3 Raft Log Read
为了确保 leader 处理读操作时仍拥有领导权,我们可以将读请求同样作为一个提案走一遍 Raft 流程,当这次读请求对应的日志可以被应用到状态机时,leader 就可以读状态机并返回给用户了。
这种读方案称为 Raft Log Read,也可以直观叫做 Read as Proposal。
为什么这种方案满足线性一致?因为该方案根据 commit index 对所有读写请求都一起做了线性化,这样每个读请求都能感知到状态机在执行完前一写请求后的最新状态,将读写日志一条一条的应用到状态机,整个系统当然满足线性一致。但该方案的缺点也非常明显,那就是性能差,读操作的开销与写操作几乎完全一致。而且由于所有操作都线性化了,我们无法并发读状态机。
6.3 Raft 读性能优化
接下来我们将介绍几种优化方案,它们在不违背系统线性一致性的前提下,大幅提升了读性能。
6.3.1 Read Index
与 Raft Log Read 相比,Read Index 省掉了同步 log 的开销,能够大幅提升读的吞吐,一定程度上降低读的时延。其大致流程为:
- Leader 在收到客户端读请求时,记录下当前的 commit index,称之为 read index。
- Leader 向 followers 发起一次心跳包,这一步是为了确保领导权,避免网络分区时少数派 leader 仍处理请求。
- 等待状态机至少应用到 read index(即 apply index 大于等于 read index)。
- 执行读请求,将状态机中的结果返回给客户端。
这里第三步的 apply index 大于等于 read index 是一个关键点。因为在该读请求发起时,我们将当时的 commit index 记录了下来,只要使客户端读到的内容在该 commit index 之后,那么结果一定都满足线性一致(如不理解可以再次回顾下前文线性一致性的例子以及2.2中的问题一)。
6.3.2 Lease Read
与 Read Index 相比,Lease Read 进一步省去了网络交互开销,因此更能显著降低读的时延。
基本思路是 leader 设置一个比选举超时(Election Timeout)更短的时间作为租期,在租期内我们可以相信其它节点一定没有发起选举,集群也就一定不会存在脑裂,所以在这个时间段内我们直接读主即可,而非该时间段内可以继续走 Read Index 流程,Read Index 的心跳包也可以为租期带来更新。
Lease Read 可以认为是 Read Index 的时间戳版本,额外依赖时间戳会为算法带来一些不确定性,如果时钟发生漂移会引发一系列问题,因此需要谨慎的进行配置。
6.3.3 Follower Read
在前边两种优化方案中,无论我们怎么折腾,核心思想其实只有两点:
- 保证在读取时的最新 commit index 已经被 apply。
- 保证在读取时 leader 仍拥有领导权。
这两个保证分别对应2.2节所描述的两个问题。
其实无论是 Read Index 还是 Lease Read,最终目的都是为了解决第二个问题。换句话说,读请求最终一定都是由 leader 来承载的。
那么读 follower 真的就不能满足线性一致吗?其实不然,这里我们给出一个可行的读 follower 方案:Follower 在收到客户端的读请求时,向 leader 询问当前最新的 commit index,反正所有日志条目最终一定会被同步到自己身上,follower 只需等待该日志被自己 commit 并 apply 到状态机后,返回给客户端本地状态机的结果即可。这个方案叫做 Follower Read。
注意:Follower Read 并不意味着我们在读过程中完全不依赖 leader 了,在保证线性一致性的前提下完全不依赖 leader 理论上是不可能做到的。
以上就是 Raft 算法的核心内容及工程实践最需要考虑的内容。
如果你坚持看了下来,相信已经对 Raft 算法的理论有了深刻的理解。当然,理论和工程实践之间存在的鸿沟可能比想象的还要大,实践中有众多的细节问题需要去面对。在后续的源码分析及实践篇中,我们会结合代码讲解到许多理论部分没有提到的这些细节点,并介绍基础架构设计的诸多经验,敬请期待!


