| Kafka的基本介绍Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。Kafka主要设计目标如下:以时间复杂度为O(1)的方… | ||||||||||||||||||

Kafka的基本介绍 Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。 主要应用场景是:日志收集系统和消息系统。 Kafka主要设计目标如下:
Kafka的设计原理分析
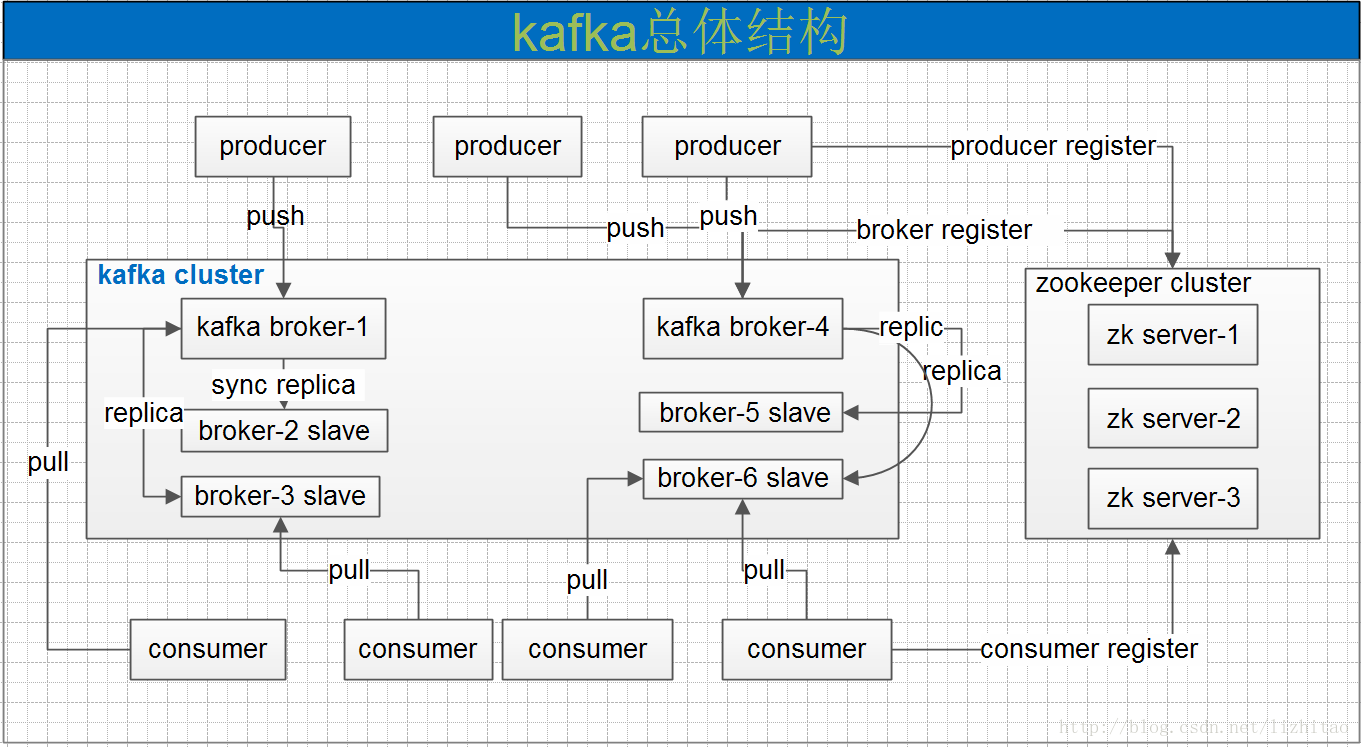
一个典型的kafka集群中包含若干producer,若干broker,若干consumer,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。 Kafka专用术语:
Kafka数据传输的事务特点
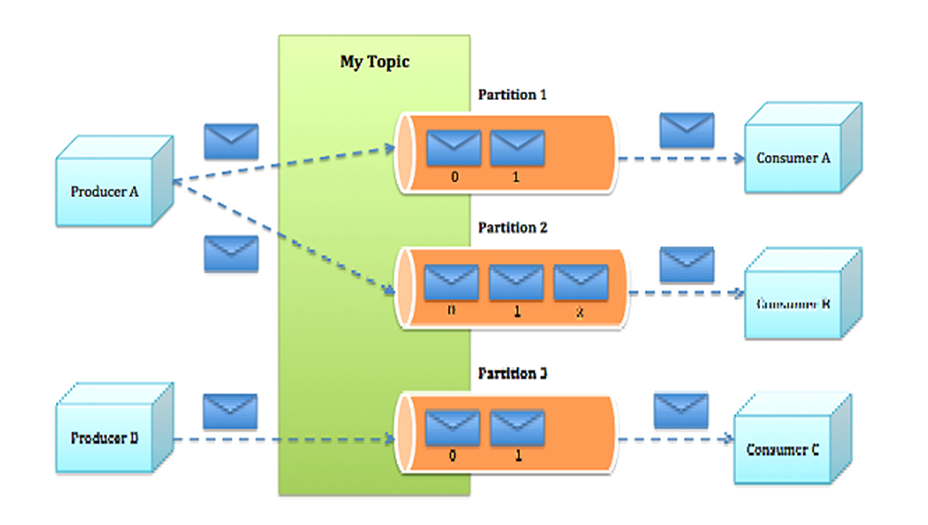
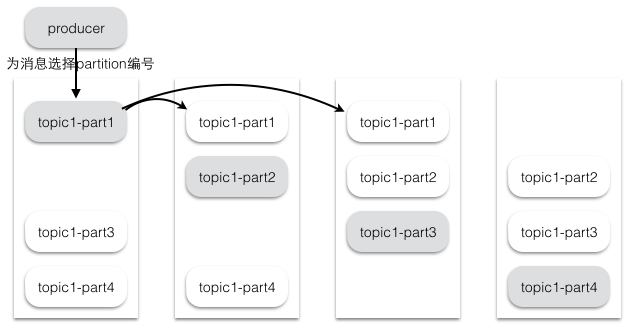
通常情况下”at-least-once”是我们首选。 Kafka消息存储格式 Topic & Partition 一个topic可以认为一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。
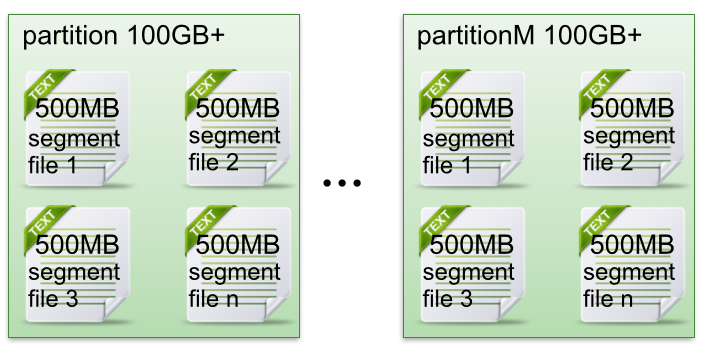
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
segment中index与data file对应关系物理结构如下:
上图中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。 其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message),以及该消息的物理偏移地址为497。 了解到segment data file由许多message组成,下面详细说明message物理结构如下:
参数说明:
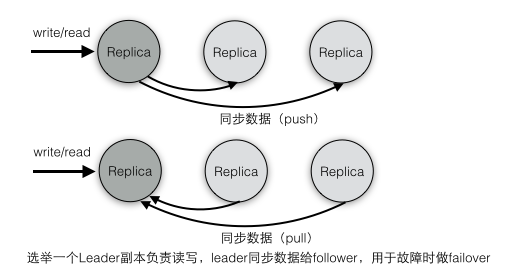
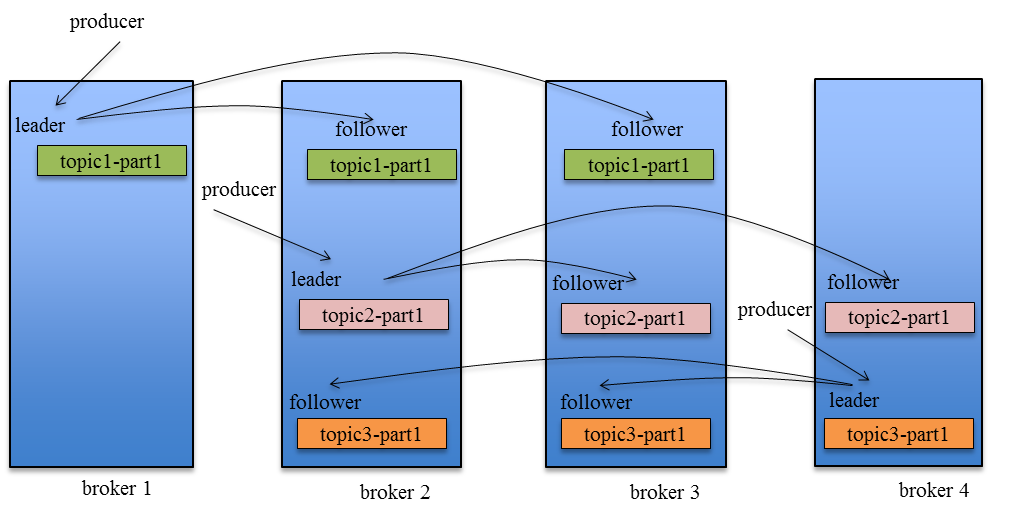
副本(replication)策略 Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。 1) 数据同步 kafka在0.8版本前没有提供Partition的Replication机制,一旦Broker宕机,其上的所有Partition就都无法提供服务,而Partition又没有备份数据,数据的可用性就大大降低了。所以0.8后提供了Replication机制来保证Broker的failover。 引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
2) 副本放置策略 为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。 Kafka分配Replica的算法如下:
假设集群一共有4个brokers,一个topic有4个partition,每个Partition有3个副本。下图是每个Broker上的副本分配情况。
3) 同步策略 Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。 为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。 Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。 Kafka Replication的数据流如下图所示:
对于Kafka而言,定义一个Broker是否“活着”包含两个条件:
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica)。如果一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader后的条数超过预定值或者Follower超过一定时间未向Leader发送fetch请求。 Kafka只解决fail/recover,一条消息只有被ISR里的所有Follower都从Leader复制过去才会被认为已提交。这样就避免了部分数据被写进了Leader,还没来得及被任何Follower复制就宕机了,而造成数据丢失(Consumer无法消费这些数据)。而对于Producer而言,它可以选择是否等待消息commit。这种机制确保了只要ISR有一个或以上的Follower,一条被commit的消息就不会丢失。 4) leader选举 Leader选举本质上是一个分布式锁,有两种方式实现基于ZooKeeper的分布式锁:
Majority Vote的选举策略和ZooKeeper中的Zab选举是类似的,实际上ZooKeeper内部本身就实现了少数服从多数的选举策略。kafka中对于Partition的leader副本的选举采用了第一种方法:为Partition分配副本,指定一个ZNode临时节点,第一个成功创建节点的副本就是Leader节点,其他副本会在这个ZNode节点上注册Watcher监听器,一旦Leader宕机,对应的临时节点就会被自动删除,这时注册在该节点上的所有Follower都会收到监听器事件,它们都会尝试创建该节点,只有创建成功的那个follower才会成为Leader(ZooKeeper保证对于一个节点只有一个客户端能创建成功),其他follower继续重新注册监听事件。 Kafka消息分组,消息消费原理 同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
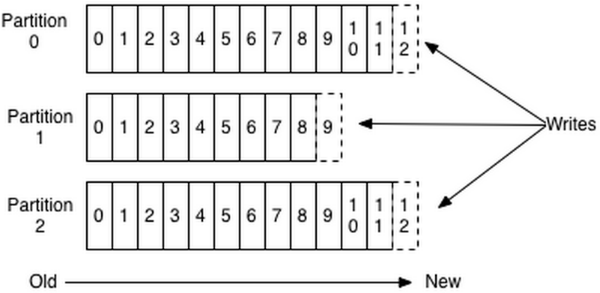
这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic。 Push vs. Pull 作为一个消息系统,Kafka遵循了传统的方式,选择由Producer向broker push消息并由Consumer从broker pull消息。 push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据Consumer的消费能力以适当的速率消费消息。 对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。 Kafak顺序写入与数据读取 生产者(producer)是负责向Kafka提交数据的,Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。 顺序写入 因为硬盘是机械结构,每次读写都会寻址,写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。 每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高。
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。
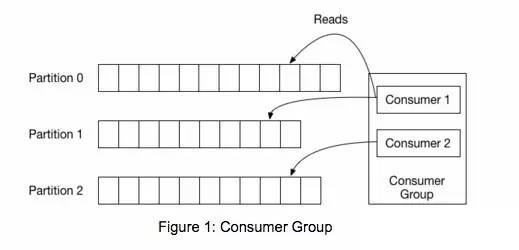
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。 在Linux Kernal 2.2之后出现了一种叫做“零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存空间的直接映射,数据不再复制到“用户态缓冲区”系统上下文切换减少2次,可以提升一倍性能。
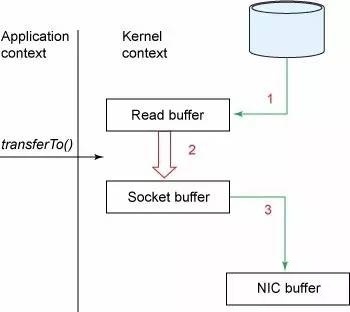
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存)。使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。) 消费者(读取数据) 试想一下,一个Web Server传送一个静态文件,如何优化?答案是zero copy。传统模式下我们从硬盘读取一个文件是这样的。
先复制到内核空间(read是系统调用,放到了DMA,所以用内核空间),然后复制到用户空间(1、2);从用户空间重新复制到内核空间(你用的socket是系统调用,所以它也有自己的内核空间),最后发送给网卡(3、4)。
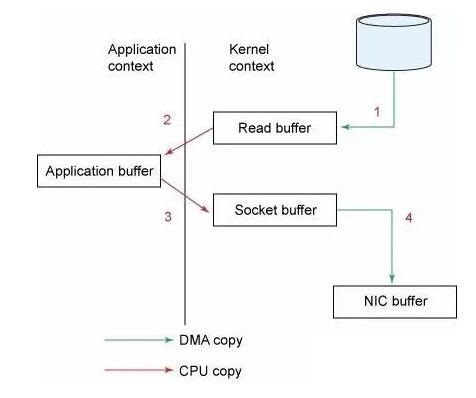
Zero Copy中直接从内核空间(DMA的)到内核空间(Socket的),然后发送网卡。这个技术非常普遍,Nginx也是用的这种技术。 实际上,Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把“文件”发送给消费者。当不需要把整个文件发出去的时候,Kafka通过调用Zero Copy的sendfile这个函数,这个函数包括:
「 浅谈大规模分布式系统中那些技术点」系列文章: Reference http://www.cnblogs.com/liuming1992/p/6423007.html http://blog.csdn.net/lifuxiangcaohui/article/details/51374862 http://www.jasongj.com/2015/01/02/Kafka深度解析 http://www.infoq.com/cn/articles/kafka-analysis-part-2 http://zqhxuyuan.github.io/2016/02/23/2016-02-23-Kafka-Controller https://tech.meituan.com/kafka-fs-design-theory.html https://my.oschina.net/silence88/blog/856195 https://toutiao.io/posts/508935/app_preview |
月份:2017年7月



[转]一个故事讲完https
今天来聊一聊https 安全传输的原理。
在开始之前,我们来虚构两个人物, 一个是位于中国的张大胖(怎么又是你?!), 还有一个是位于米国的Bill (怎么还是你?!)。
这俩哥们隔着千山万水,通过网络联系上了, 两个人臭味相投,聊得火热。
此时正值米国大选, 张大胖亲切地“致电”Bill, 对米国总统大选的情况表示强烈地关注。 Bill则回电说谢谢关心米国人的事情我们米国人自己做主,不用你们歪果仁瞎操心……
张大胖继续“致电”说其实我们支持特朗普, 因为希拉里太情绪化,太难打交道了, 我们挺希望看到特朗普上台这样米国就会变成 The Divided State of America ……
Bill 回电: 拉倒你吧你, 我们米国的政体有着强大的纠错性, 虽然有时候发展得慢, 有时候会走上岔路, 但很快就会回到正途,几百年来稳定得很,不像你们像坐了过山车一样…..
两个人越聊越投机,天南地北,海阔天空,还夹杂着不少隐私的话题。
有一天, Bill 突然意识到: 坏了, 我们的通信是明文的, 这简直就是网络上裸奔啊, 任何一个不怀好意的家伙都可以监听我们通信,打开我们发送的数据包,窥探我们的隐私啊。
张大胖说: “你不早点说,我刚才是不是把我的微信号给你发过去了? 我是不是告诉你我上周去哪儿旅游了? 估计已经被人截取了吧!”
Bill 提议: “要不我们做个数据的加密? 每次传输之前, 你把消息用一个加密算法加密, 然后发到我这里以后我再解密, 这样别人就无法偷窥了,像这样: ”
张大胖冰雪聪明,一看就明白了, 这加密和解密算法是公开的,那个密钥是保密的, 只有两人才知道, 这样生成的加密消息(密文) 别人就无法得知了。 他说: “Bill 老兄,你生成一个密钥, 然后把密钥发给我, 咱们这就开启加密消息, 让那些偷窥狂人们哭去吧!”
(码农翻身注:这叫对称加密算法, 因为加密和解密用的是同一个密钥)
一炷香功夫过去了, Bill 还是没有回音, 张大胖忍不住地催促: “快发啊?!!!”
Bill 终于回复了: “ 我感觉有一双眼睛正在虎视眈眈地盯着我们的通话, 如果我把密钥发给你, 也被他截取了, 那加密岂不白费工夫?”
张大胖沉默了, 是啊, 网络是不安全的, 这密钥怎么安全地发过来啊 ?
“奥,对了,我下周要去米国旅游,到时候我们见一面,把密码确定下来,写到纸上,谁也偷不走, 这不就结了?”
“哈哈, 这倒是终极解决之道 ” Bill 笑了, “不过,我不仅仅和你聊天, 我还要和易卜拉欣,阿卜杜拉, 弗拉基米尔,克里斯托夫,玛格丽特, 桥本龙太郎, 李贤俊, 许木木,郭芙蓉,吕秀才等人通信, 我总不能打着飞的,满世界的和人交换密码吧? ”
张大胖心里暗自佩服Bill同学的好友竟然遍布全球,看来他对加密通信的要求更加强烈啊!
可是这个加密解密算法需要的密钥双方必须得知道啊, 但是密钥又无法通过网络发送, 这该死的偷窥者!
Bill 和 张大胖的通信无法加密,说话谨慎了不少, 直到有一天, 他们听说了一个叫做RSA的非对称加密算法,一下子来了灵感。
这个RSA算法非常有意思,它不是像之前的算法, 双方必须协商一个保密的密钥, 而是有一对儿钥匙, 一个是保密的,称为私钥,另外一个是公开的,称为公钥。
更有意思的是,用私钥加密的数据,只有对应的公钥才能解密,用公钥加密的数据, 只有对应的私钥才能解密。
有了这两个漂亮的特性, 当张大胖给Bill发消息的时候, 就可以先用Bill的公钥去加密(反正Bill的公钥是公开的,地球人都知道), 等到消息被Bill 收到后, 他就可以用自己的私钥去解密(只有Bill才能解开,私钥是保密的 )
反过来也是如此, 当Bill 想给张大胖发消息的时候,就用张大胖的公钥加密, 张大胖收到后,就用自己的私钥解密。
这样以来,通信安全固若金汤, 没有任何人能窥探他们的小秘密了。
两人实验了几次, 张大胖说: “Bill , 你有没有感觉这个RSA的加密和解密有点慢啊?”
Bill叹了口气 :“是啊, 我也注意到了, 刚才搜了一下,这个RSA算法比之前的对称密钥算法要慢上百倍。我们就是加个密而已,现在搞得都没法用了”
“回到咱们最初的问题,我们想用一个密钥来加密通信,那个对称加密算法是非常快的,但是苦于密钥无法安全传输, 现在有了RSA ,我想可以结合一下, 分两步走 (1) 我生成一个对称加密算法的密钥, 用RSA的方式安全发给你, (2) 我们随后就不用RSA了, 只用这个密钥,利用对称加密算法来通信, 如何? ”
Bill 说: “你小子可以啊, 这样以来既解决了密钥的传递问题, 又解决了RSA速度慢的问题,不错。”
于是两人就安全地传递了对称加密的密钥, 用它来加密解密,果然快多了!
张大胖把和Bill 聊天的情况给老婆汇报了一次。
老婆告诫他说: “你要小心啊, 你确定网络那边坐着的确实是Bill ?”
张大胖着急地辩解说:“肯定是他啊,我都有他的公钥,我们俩的通信都是加密的。”
老婆提醒道:"假如啊,Bill给你发公钥的时候, 有个中间人,截取了Bill的公钥, 然后把自己的公钥发给了你,冒充Bill ,你发的消息就用中间人的公钥加了密, 那中间人不就可以解密看到消息了?"
张大胖背后出汗了,是啊,这个中间人解密以后,还可以用Bill的公钥加密,发给Bill , Bill和我根本都意识不到, 还以为我们在安全传输呢!
看来问题出现在公钥的分发上! 虽然这个东西是公开的, 但是在别有用心的人看来,截取以后还可以干坏事 !
但是怎么安全地分发公钥呢? 似乎又回到了最初的问题: 怎么安全的保护密钥?
可是似乎和最初的问题还不一样,这一次的公钥不用保密,但是一定得有个办法声明这个公钥确实是Bill的, 而不是别人的。
怎么声明呢?
张大胖突然想到: 现实中有公证处,它提供的公证材料大家都信任,那在网络世界也可以建立一个这样的具备公信力的认证中心, 这个中心给大家颁发一个证书, 用于证明一个人的身份。
这个证书里除了包含一个人的基本信息之外,还有包括最关键的一环:这个人的公钥!
这样以来我拿到证书就可以安全地取到公钥了 ! 完美!
可是Bill 马上泼了一盆冷水:证书怎么安全传输? 要是证书传递的过程中被篡改了怎么办?
张大胖心里不由地咒骂起来: 我操, 这简直就是鸡生蛋,蛋生鸡的问题啊。
天无绝人之路, 张大胖很快就找到了突破口: 数字签名。
简单来讲是这样的, Bill可以把他的公钥和个人信息用一个Hash算法生成一个消息摘要, 这个Hash算法有个极好的特性,只要输入数据有一点点变化,那生成的消息摘要就会有巨变,这样就可以防止别人修改原始内容。
可是作为攻击者的中间人笑了: “虽然我没办法改公钥,但是我可以把整个原始信息都替换了, 生成一个新的消息摘要, 你不还是辨别不出来?”
张大胖说你别得意的太早 , 我们会让有公信力的认证中心(简称CA)用它的私钥对消息摘要加密,形成签名:
这还不算, 还把原始信息和数据签名合并, 形成一个全新的东西,叫做“数字证书”
张大胖接着说:当Bill把他的证书发给我的时候, 我就用同样的Hash 算法, 再次生成消息摘要,然后用CA的公钥对数字签名解密, 得到CA创建的消息摘要, 两者一比,就知道有没有人篡改了!
如果没人篡改, 我就可以安全的拿到Bill的公钥喽,有了公钥, 后序的加密工作就可以开始了。
虽然很费劲, 但是为了防范你们这些偷窥者,实在是没办法啊。
中间人恶狠狠地说: “算你小子狠! 等着吧,我还有别的招。 对了,我且问你, 你这个CA的公钥怎么拿到? 难道不怕我在你传输CA公钥的时候发起中间人攻击吗? 如果我成功的伪装成了CA,你这一套体系彻底玩完。”
张大胖语塞了,折腾了半天,又回到了公钥安全传输的问题!
不过转念一想,想解决鸡生蛋,蛋生鸡的问题必须得打破这个怪圈才行,我必须得信任CA,并且通过安全的的方式获取他们的公钥,这样才能把游戏玩下去。
(公众号码农翻身注:这些CA本身也有证书来证明自己的身份,并且CA的信用是像树一样分级的,高层的CA给底层的CA做信用背书,而操作系统/浏览器中会内置一些顶层的CA的证书,相当于你自动信任了他们。 这些顶层的CA证书一定得安全地放入操作系统/浏览器当中,否则世界大乱。)
终于可以介绍https了,前面已经介绍了https的原理, 你把张大胖替换成浏览器, 把Bill 替换成某个网站就行了。
一个简化的(例如下图没有包含Pre-Master Secret)https流程图是这样的, 如果你理解了前面的原理,这张图就变得非常简单:
(完)
另外如何防止中间人攻击:比如A发送内容给B,防止中间人C拆改内容,需要发送内容包含:B公钥加密(内容)+A私钥加密(内容hash),这样中间人只能看到hash,但是改hash对方就能发现,防止了中间人的攻击;
[转]Linux Kernel 4.9 中的 BBR 算法与之前的 TCP 拥塞控制相比有什么优势?
[原文链接]https://www.zhihu.com/question/53559433
中国科大 LUG 的 @高一凡 在 LUG HTTP 代理服务器上部署了 Linux 4.9 的 TCP BBR 拥塞控制算法。从科大的移动出口到新加坡 DigitalOcean 的实测下载速度从 647 KB/s 提高到了 22.1 MB/s(截屏如下)。
 (应评论区各位 dalao 要求,补充测试环境说明:是在新加坡的服务器上设置了 BBR,新加坡的服务器是数据的发送方。这个服务器是访问墙外资源的 HTTP 代理。科大移动出口到 DigitalOcean 之间不是 dedicated 的专线,是走的公网,科大移动出口这边是 1 Gbps 无限速(但是要跟其他人 share),DigitalOcean 实测是限速 200 Mbps。RTT 是 66 ms。实测结果这么好,也是因为大多数人用的是 TCP Cubic (Linux) / Compound TCP (Windows),在有一定丢包率的情况下,TCP BBR 更加激进,抢占了更多的公网带宽。因此也是有些不道德的感觉。)
(应评论区各位 dalao 要求,补充测试环境说明:是在新加坡的服务器上设置了 BBR,新加坡的服务器是数据的发送方。这个服务器是访问墙外资源的 HTTP 代理。科大移动出口到 DigitalOcean 之间不是 dedicated 的专线,是走的公网,科大移动出口这边是 1 Gbps 无限速(但是要跟其他人 share),DigitalOcean 实测是限速 200 Mbps。RTT 是 66 ms。实测结果这么好,也是因为大多数人用的是 TCP Cubic (Linux) / Compound TCP (Windows),在有一定丢包率的情况下,TCP BBR 更加激进,抢占了更多的公网带宽。因此也是有些不道德的感觉。)
此次 Google 提交到 Linux 主线并发表在 ACM queue 期刊上的 TCP BBR 拥塞控制算法,继承了 Google “先在生产环境部署,再开源和发论文” 的研究传统。TCP BBR 已经在 Youtube 服务器和 Google 跨数据中心的内部广域网(B4)上部署。
TCP BBR 致力于解决两个问题:
- 在有一定丢包率的网络链路上充分利用带宽。
- 降低网络链路上的 buffer 占用率,从而降低延迟。
TCP 拥塞控制的目标是最大化利用网络上瓶颈链路的带宽。一条网络链路就像一条水管,要想用满这条水管,最好的办法就是给这根水管灌满水,也就是:
水管内的水的数量 = 水管的容积 = 水管粗细 × 水管长度
换成网络的名词,也就是:
网络内尚未被确认收到的数据包数量 = 网络链路上能容纳的数据包数量 = 链路带宽 × 往返延迟
TCP 维护一个发送窗口,估计当前网络链路上能容纳的数据包数量,希望在有数据可发的情况下,回来一个确认包就发出一个数据包,总是保持发送窗口那么多个包在网络中流动。
TCP 与水管的类比示意(图片来源:Van Jacobson,Congestion Avoidance and Control,1988)
如何估计水管的容积呢?一种大家都能想到的方法是不断往里灌水,直到溢出来为止。标准 TCP 中的拥塞控制算法也类似:不断增加发送窗口,直到发现开始丢包。这就是所谓的 ”加性增,乘性减”,也就是当收到一个确认消息的时候慢慢增加发送窗口,当确认一个包丢掉的时候较快地减小发送窗口。
标准 TCP 的这种做法有两个问题:
首先,假定网络中的丢包都是由于拥塞导致(网络设备的缓冲区放不下了,只好丢掉一些数据包)。事实上网络中有可能存在传输错误导致的丢包,基于丢包的拥塞控制算法并不能区分拥塞丢包和错误丢包。在数据中心内部,错误丢包率在十万分之一(1e-5)的量级;在广域网上,错误丢包率一般要高得多。
更重要的是,“加性增,乘性减” 的拥塞控制算法要能正常工作,错误丢包率需要与发送窗口的平方成反比。数据中心内的延迟一般是 10-100 微秒,带宽 10-40 Gbps,乘起来得到稳定的发送窗口为 12.5 KB 到 500 KB。而广域网上的带宽可能是 100 Mbps,延迟 100 毫秒,乘起来得到稳定的发送窗口为 10 MB。广域网上的发送窗口比数据中心网络高 1-2 个数量级,错误丢包率就需要低 2-4 个数量级才能正常工作。因此标准 TCP 在有一定错误丢包率的长肥管道(long-fat pipe,即延迟高、带宽大的链路)上只会收敛到一个很小的发送窗口。这就是很多时候客户端和服务器都有很大带宽,运营商核心网络也没占满,但下载速度很慢,甚至下载到一半就没速度了的一个原因。
其次,网络中会有一些 buffer,就像输液管里中间膨大的部分,用于吸收网络中的流量波动。由于标准 TCP 是通过 “灌满水管” 的方式来估算发送窗口的,在连接的开始阶段,buffer 会被倾向于占满。后续 buffer 的占用会逐渐减少,但是并不会完全消失。客户端估计的水管容积(发送窗口大小)总是略大于水管中除去膨大部分的容积。这个问题被称为 bufferbloat(缓冲区膨胀)。
缓冲区膨胀现象图示
缓冲区膨胀有两个危害:
- 增加网络延迟。buffer 里面的东西越多,要等的时间就越长嘛。
- 共享网络瓶颈的连接较多时,可能导致缓冲区被填满而丢包。很多人把这种丢包认为是发生了网络拥塞,实则不然。
往返延迟随时间的变化。红线:标准 TCP(可见周期性的延迟变化,以及 buffer 几乎总是被填满);绿线:TCP BBR
(图片引自 Google 在 ACM queue 2016 年 9-10 月刊上的论文 [1],下同)
有很多论文提出在网络设备上把当前缓冲区大小的信息反馈给终端,比如在数据中心广泛应用的 ECN(Explicit Congestion Notification)。然而广域网上网络设备众多,更新换代困难,需要网络设备介入的方案很难大范围部署。
TCP BBR 是怎样解决以上两个问题的呢?
- 既然不容易区分拥塞丢包和错误丢包,TCP BBR 就干脆不考虑丢包。
- 既然灌满水管的方式容易造成缓冲区膨胀,TCP BBR 就分别估计带宽和延迟,而不是直接估计水管的容积。
带宽和延迟的乘积就是发送窗口应有的大小。发明于 2002 年并已进入 Linux 内核的 TCP Westwood 拥塞控制算法,就是分别估计带宽和延迟,并计算其乘积作为发送窗口。然而带宽和延迟就像粒子的位置和动量,是没办法同时测准的:要测量最大带宽,就要把水管灌满,缓冲区中有一定量的数据包,此时延迟就是较高的;要测量最低延迟,就要保证缓冲区为空,网络里的流量越少越好,但此时带宽就是较低的。
TCP BBR 解决带宽和延迟无法同时测准的方法是:交替测量带宽和延迟;用一段时间内的带宽极大值和延迟极小值作为估计值。
在连接刚建立的时候,TCP BBR 采用类似标准 TCP 的慢启动,指数增长发送速率。然而标准 TCP 遇到任何一个丢包就会立即进入拥塞避免阶段,它的本意是填满水管之后进入拥塞避免,然而(1)如果链路的错误丢包率较高,没等到水管填满就放弃了;(2)如果网络里有 buffer,总要把缓冲区填满了才会放弃。
TCP BBR 则是根据收到的确认包,发现有效带宽不再增长时,就进入拥塞避免阶段。(1)链路的错误丢包率只要不太高,对 BBR 没有影响;(2)当发送速率增长到开始占用 buffer 的时候,有效带宽不再增长,BBR 就及时放弃了(事实上放弃的时候占的是 3 倍带宽 × 延迟,后面会把多出来的 2 倍 buffer 清掉),这样就不会把缓冲区填满。
发送窗口与往返延迟和有效带宽的关系。BBR 会在左右两侧的拐点之间停下,基于丢包的标准 TCP 会在右侧拐点停下(图片引自 TCP BBR 论文,下同)
在慢启动过程中,由于 buffer 在前期几乎没被占用,延迟的最小值就是延迟的初始估计;慢启动结束时的最大有效带宽就是带宽的初始估计。
慢启动结束后,为了把多占用的 2 倍带宽 × 延迟消耗掉,BBR 将进入排空(drain)阶段,指数降低发送速率,此时 buffer 里的包就被慢慢排空,直到往返延迟不再降低。如下图绿线所示。
TCP BBR(绿线)与标准 TCP(红线)有效带宽和往返延迟的比较
排空阶段结束后,BBR 进入稳定运行状态,交替探测带宽和延迟。由于网络带宽的变化比延迟的变化更频繁,BBR 稳定状态的绝大多数时间处于带宽探测阶段。带宽探测阶段是一个正反馈系统:定期尝试增加发包速率,如果收到确认的速率也增加了,就进一步增加发包速率。
具体来说,以每 8 个往返延迟为周期,在第一个往返的时间里,BBR 尝试增加发包速率 1/4(即以估计带宽的 5/4 速度发送)。在第二个往返的时间里,为了把前一个往返多发出来的包排空,BBR 在估计带宽的基础上降低 1/4 作为发包速率。剩下 6 个往返的时间里,BBR 使用估计的带宽发包。
当网络带宽增长一倍的时候,每个周期估计带宽会增长 1/4,每个周期为 8 个往返延迟。其中向上的尖峰是尝试增加发包速率 1/4,向下的尖峰是降低发包速率 1/4(排空阶段),后面 6 个往返延迟,使用更新后的估计带宽。3 个周期,即 24 个往返延迟后,估计带宽达到增长后的网络带宽。
网络带宽增长一倍时的行为。绿线为网络中包的数量,蓝线为延迟
当网络带宽降低一半的时候,多出来的包占用了 buffer,导致网络中包的延迟显著增加(下图蓝线),有效带宽降低一半。延迟是使用极小值作为估计,增加的实际延迟不会反映到估计延迟(除非在延迟探测阶段,下面会讲)。带宽的估计则是使用一段滑动窗口时间内的极大值,当之前的估计值超时(移出滑动窗口)之后,降低一半后的有效带宽就会变成估计带宽。估计带宽减半后,发送窗口减半,发送端没有窗口无法发包,buffer 被逐渐排空。
网络带宽降低一半时的行为。绿线为网络中包的数量,蓝线为延迟
当带宽增加一倍时,BBR 仅用 1.5 秒就收敛了;而当带宽降低一半时,BBR 需要 4 秒才能收敛。前者由于带宽增长是指数级的;后者主要是由于带宽估计采用滑动窗口内的极大值,需要一定时间有效带宽的下降才能反馈到带宽估计中。
当网络带宽保持不变的时候,稳定状态下的 TCP BBR 是下图这样的:(我们前面看到过这张图)可见每 8 个往返延迟为周期的延迟细微变化。
往返延迟随时间的变化。红线:标准 TCP;绿线:TCP BBR
上面介绍了 BBR 稳定状态下的带宽探测阶段,那么什么时候探测延迟呢?在带宽探测阶段中,估计延迟始终是使用极小值,如果实际延迟真的增加了怎么办?TCP BBR 每过 10 秒,如果估计延迟没有改变(也就是没有发现一个更低的延迟),就进入延迟探测阶段。延迟探测阶段持续的时间仅为 200 毫秒(或一个往返延迟,如果后者更大),这段时间里发送窗口固定为 4 个包,也就是几乎不发包。这段时间内测得的最小延迟作为新的延迟估计。也就是说,大约有 2% 的时间 BBR 用极低的发包速率来测量延迟。
TCP BBR 还使用 pacing 的方法降低发包时的 burstiness,减少突然传输的一串包导致缓冲区膨胀。发包的 burstiness 可能由两个原因引起:
- 数据接收方为了节约带宽,把多个确认(ACK)包累积成一个发出,这叫做 ACK Compression。数据发送方收到这个累积确认包后,如果没有 pacing,就会发出一连串的数据包。
- 数据发送方没有足够的数据可传输,积累了一定量的空闲发送窗口。当应用层突然需要传输较多的数据时,如果没有 pacing,就会把空闲发送窗口大小这么多数据一股脑发出去。
下面我们来看 TCP BBR 的效果如何。
首先看 BBR 试图解决的第一个问题:在有随机丢包情况下的吞吐量。如下图所示,只要有万分之一的丢包率,标准 TCP 的带宽就只剩 30%;千分之一丢包率时只剩 10%;有百分之一的丢包率时几乎就卡住了。而 TCP BBR 在丢包率 5% 以下几乎没有带宽损失,在丢包率 15% 的时候仍有 75% 带宽。
100 Mbps,100ms 下的丢包率和有效带宽(红线:标准 TCP,绿线:TCP BBR)
异地数据中心间跨广域网的传输往往是高带宽、高延迟的,且有一定丢包率,TCP BBR 可以显著提高传输速度。这也是中国科大 LUG HTTP 代理服务器和 Google 广域网(B4)部署 TCP BBR 的主要原因。
再来看 BBR 试图解决的第二个问题:降低延迟,减少缓冲区膨胀。如下图所示,标准 TCP 倾向于把缓冲区填满,缓冲区越大,延迟就越高。当用户的网络接入速度很慢时,这个延迟可能超过操作系统连接建立的超时时间,导致连接建立失败。使用 TCP BBR 就可以避免这个问题。
缓冲区大小与延迟的关系(红线:标准 TCP,绿线:TCP BBR)
Youtube 部署了 TCP BBR 之后,全球范围的中位数延迟降低了 53%(也就是快了一倍),发展中国家的中位数延迟降低了 80%(也就是快了 4 倍)。从下图可见,延迟越高的用户,采用 TCP BBR 后的延迟下降比例越高,原来需要 10 秒的现在只要 2 秒了。如果您的网站需要让用 GPRS 或者慢速 WiFi 接入网络的用户也能流畅访问,不妨试试 TCP BBR。
标准 TCP 与 TCP BBR 的往返延迟中位数之比
综上,TCP BBR 不再使用丢包作为拥塞的信号,也不使用 “加性增,乘性减” 来维护发送窗口大小,而是分别估计极大带宽和极小延迟,把它们的乘积作为发送窗口大小。
BBR 的连接开始阶段由慢启动、排空两阶段构成。为了解决带宽和延迟不易同时测准的问题,BBR 在连接稳定后交替探测带宽和延迟,其中探测带宽阶段占绝大部分时间,通过正反馈和周期性的带宽增益尝试来快速响应可用带宽变化;偶尔的探测延迟阶段发包速率很慢,用于测准延迟。
BBR 解决了两个问题:
- 在有一定丢包率的网络链路上充分利用带宽。非常适合高延迟、高带宽的网络链路。
- 降低网络链路上的 buffer 占用率,从而降低延迟。非常适合慢速接入网络的用户。
看到评论区很多客户端和服务器哪个部署 TCP BBR 有效的问题,需要提醒:TCP 拥塞控制算法是数据的发送端决定发送窗口,因此在哪边部署,就对哪边发出的数据有效。如果是下载,就应在服务器部署;如果是上传,就应在客户端部署。
如果希望加速访问国外网站的速度,且下载流量远高于上传流量,在客户端上部署 TCP BBR(或者任何基于 TCP 拥塞控制的加速算法)是没什么效果的。需要在 VPN 的国外出口端部署 TCP BBR,并做 TCP Termination & TCP Proxy。也就是客户建立连接事实上是跟 VPN 的国外出口服务器建联,国外出口服务器再去跟目标服务器建联,使得丢包率高、延迟大的这一段(从客户端到国外出口)是部署了 BBR 的国外出口服务器在发送数据。或者在 VPN 的国外出口端部署 BBR 并做 HTTP(S) Proxy,原理相同。
大概是由于 ACM queue 的篇幅限制和目标读者,这篇论文并没有讨论(仅有拥塞丢包情况下)TCP BBR 与标准 TCP 的公平性。也没有讨论 BBR 与现有拥塞控制算法的比较,如基于往返延迟的(如 TCP Vegas)、综合丢包和延迟因素的(如 Compound TCP、TCP Westwood+)、基于网络设备提供拥塞信息的(如 ECN)、网络设备采用新调度策略的(如 CoDel)。期待 Google 发表更详细的论文,也期待各位同行报告 TCP BBR 在实验或生产环境中的性能。
本人不是 TCP 拥塞控制领域的专家,如有错漏不当之处,恳请指正。
[转]mysql分区表的原理和优缺点
1.分区表的原理
分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
在分区表上的操作按照下面的操作逻辑进行:
select查询:
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据
insert操作:
当写入一条记录时,分区层打开并锁住所有的底层表,然后确定哪个分区接受这条记录,再将记录写入对应的底层表
delete操作:
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作
update操作:
当更新一条数据时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据应该放在哪个分区,然后对底层表进行写入操作,并对原数据所在的底层表进行删除操作
虽然每个操作都会打开并锁住所有的底层表,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,如:innodb,则会在分区层释放对应的表锁,这个加锁和解锁过程与普通Innodb上的查询类似。
2.在下面的场景中,分区可以起到非常大的作用:
A:表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他都是历史数据
B:分区表的数据更容易维护,如:想批量删除大量数据可以使用清除整个分区的方式。另外,还可以对一个独立分区进行优化、检查、修复等操作
C:分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备
D:可以使用分区表来避免某些特殊的瓶颈,如:innodb的单个索引的互斥访问,ext3文件系统的inode锁竞争等
E:如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果非常好
F:优化查询,在where字句中包含分区列时,可以只使用必要的分区来提高查询效率,同时在涉及sum()和count()这类聚合函数的查询时,可以在每个分区上面并行处理,最终只需要汇总所有分区得到的结果。
3.分区本身也有一些限制:
A:一个表最多只能有1024个分区(mysql5.6之后支持8192个分区)
B:在mysql5.1中分区表达式必须是整数,或者是返回整数的表达式,在5.5之后,某些场景可以直接使用字符串列和日期类型列来进行分区(使用varchar字符串类型列时,一般还是字符串的日期作为分区)。
C:如果分区字段中有主键或者唯一索引列,那么所有主键列和唯一索引列都必须包含进来,如果表中有主键或唯一索引,那么分区键必须是主键或唯一索引
D:分区表中无法使用外键约束
E:mysql数据库支持的分区类型为水平分区,并不支持垂直分区,因此,mysql数据库的分区中索引是局部分区索引,一个分区中既存放了数据又存放了索引,而全局分区是指的数据库放在各个分区中,但是所有的数据的索引放在另外一个对象中
F:目前mysql不支持空间类型和临时表类型进行分区。不支持全文索引
4.子分区的建立需要注意以下几个问题:
A:每个子分区的数量必须相同
B:只要在一个分区表的任何分区上使用subpartition来明确定义任何子分区,就必须在所有分区上定义子分区,不能漏掉一些分区不进行子分区。
C:每个subpartition子句必须包括子分区的一个名字
D:子分区的名字必须是唯一的,不能在一张表中出现重名的子分区
E:mysql数据库的分区总是把null当作比任何非null更小的值,这和数据库中处理null值的order by操作是一样的,升序排序时null总是在最前面,因此对于不同的分区类型,mysql数据库对于null的处理也各不相同。对于range分区,如果向分区列插入了null,则mysql数据库会将该值放入最左边的分区,注意,如果删除分区,分区下的所有内容都从磁盘中删掉了,null所在分区被删除,null值也就跟着被删除了。在list分区下要使用null,则必须显式地定义在分区的散列值中,否则插入null时会报错。hash和key分区对于null的处理方式和range,list分区不一样,任何分区函数都会将null返回为0.
[转]滴滴打车passport系统架构设计分析
我们在 passport 设计时候踩过很多坑,后来在可用性方面做了很多优化实践,今天给大家分享其中的 7 个小优化。
我的题目就指出了 Passport 设计的一切都是为了高可用。Passport 主要有两个功能,第一登录;第二,授权或者鉴权,每一个请求过来,我这边都会做一个校验,校验量是比较大的。再考虑到滴滴的场景,我们在座的大家可能是乘客端,但是我们还有司机端、代驾端等,司机端每一秒都会发请求过来,请求方就会到 Passport 请求一下,所以是一个典型的高并发高可用场景。
业务场景
先简单介绍一下业务场景,我来自滴滴平台部门,平台是一个业务支撑部门,支付、账号、消息等功能都会在我们平台里。今天主要给大家介绍账号子系统,我们设计 Passport,有很多优化的规则,比如大系统做小,做服务拆分,力度拆得非常小,目的是为了高可用。
Passport 的应用场景,工作之一就是登录。登录成功之后返回 ticket,之后每一个业务请求都会把 ticket 传过来,如果合法,则返回给调用方用户真实的信息。

Passport 简单理解,它是三元组。登录的凭证是手机号码、密码、UID,可以简单理解为 Passport 只维护了三元组。
在我们开始设计一个账户,用户其他资料一开始揉在一起设计,后来我们发现这个问题非常麻烦,可用性会存在一些瓶颈,因此把大系统做小,把 Passport 单独拆出来,只包括这三元组。
一切为了高可用
我的第二个分享内容是一切为了高可用,我们做了什么?我们会从编程语言上,最早用 PHP 写的现在用 golang。最小闭环,柔性降级,异地多活,访问控制,接口拆分等。
1. 选用什么编程语言
我们编程语言是 PHP,现在账号系统用 golang,提升非常明显。有一个例子,一个乘客的用户服务,在线上布了 45 个实例,司机端或者乘客端都有心跳,每一个端有点像 ddos 攻击一样,不停的轮询,司机要不停上报他的状态或者坐标等等信息,访问量非常大。一开始用 45 台 PHP,后面用 golang 重写了一下,只用 6 台机解决了这个问题。
2. 最小闭环(大系统小做)
刚才也说到用户的资料包括 count、UID、密码、名字等信息,我们把它做了一个拆分。拆分有什么作用?和我之前在腾讯的经历有关系。之前在腾讯的时候,老大一直说 QQ 永远不能存在不登录情况下,即时登录进去都是空白都能接受。这个的确有很大的差异,当用户不能登录,他以为他的账户被盗了,这会形成很大的惶恐,但登录之后什么都没有,他知道肯定是系统挂了,不会有恐慌的心理。因此对于帐号系统来说,需要永远要保证它是能登录的。
最小闭环刚才说了,passport 只包括三个最主要的属性。我们乘客端刚刚上了密码登录,司机端都是用密码登录。在 QQ 时登录量是非常大的,校验量非常大需要做很多细致的工作。腾讯包括微信的架构都有一条经典的经验,大系统小做,当你把系统做小之后,高可用性最容易做,每一个功能比如用户存储的信息越多,这个事情就越难一些。
3. 柔性及可降级之 Ticket 设计
很多公司都需要降级,在柔性降级里面举几个例子跟大家分享。
在移动客户端应用,登录时间通常是很长的。比如大家用微信,不需要经常登录,但是服务端需要有踢出用户的能力。踢出是什么概念?登录后,可以用另外一个手机登录就把前一个踢出,这样应用就会更安全。就因为可踢出,实现就会稍微复杂一点。
我加入滴滴之前已经存在一个 Passport,最早是 PHP 语言写的。在滴滴合并快的,我也了解快的那边的情况,大家在设计 ticket 时比较简单和类似,一登录,生成一个 ticket,业务来请求提供认证,认证服务和 ticket 进行对比,对的就通过,不对就让用户踢出。

我相信很多帐号系统都是这样实现,但这里面隐藏比较严重的问题。ticket 是无语义的,里面没有任何信息。其次如果 ticket 服务不稳定校验就会不通过,所有的业务请求第一步就是来校验,它对系统的要求,第一是低延时,你得足够稳定足够快。第二,不能有故障,一旦你个服务失败,用户端就会请求失败,就叫不到车。
在滴滴,不管基础组件比如 MySQL 都需要考虑失败的情况,和滴滴快速成长有一定的关系,所有业务系统,在实现时就需要充分考虑系统的不可靠性。
于是我们对 ticket 重新进行设计,下图是目前的设计。第一我们 ticket 增加了语义,里面是有内容进行了加密。这里面提一点,加解密尽量不要用 RSA 非对称算法,那会是一个灾难。ticket 里面包含一些信息,包括手机号、UID、密码。

图上面有一个 seq,可能是我们这边比较独特的设计,你要实现可踢除,就像前图更多是对比两个 ticket 是不是对等,ticket 比较大是一个串,放在一个存储里面,空间挺大,并且不停地变,我们想把它改造成 seq,一个四字节的 int,通过 seq 达到 ticket 踢除的目的。
在用户登录的时候发 ticket,ticket 有 seq,跟手机号加密在里面,每登录一次我会 seq + 1,我们有状态的是 seq,由很长的存储变成 int。我们验证 ticket 是否有效?只需要解密,把 seq 拿出来,跟数据库 seq 对比是不是一样?一样,就过了。
这个项目我说了几点。第一,我用 token 的概念,实际上是没用,把它干掉,通过有状态的 seq 做到。另外,ticket 里面是自己包含内容是有语义的,这为我们降级各方面做了很多的探索,我们在降级的情况下会牺牲一点点的安全性。刚才说 Seq,由 ticket 变成 seq,存储下降非常多。
这里实例说的还是柔性降级,假设 seq 存在 cache 里面,cache 这一级挂了,我们还是能够做到验证 seq,能解密,seq 判断符合要求,在降级的情况下也是可以过的。当然这也牺牲了一点安全性。
4. 柔性及可降级之短信验证码
我们最早大部分登录使用验证码,另外我们系统有很多的入口,我们在腾讯的微信、支付宝里面都有访问入口。在 Web 环境下系统很容易被攻击,后面我会讲攻击的事情。
登录时候,输手机,发验证码,输入验证码,然后到我这边服务端做校验。通常做法也是用户点获取验证码,验证码有效期几分钟,系统存储一个手机号跟 code(验证码)的关系,登录的时候把手机号跟 code 传进来。

验证时候根据手机号找到存储里面 code,两个一比,相同就通过了。但是也有问题,假如 cache 挂了,登录不了就会很被动,如何实现高可用?
Cache 复制永远高可用是另外一个话题,我们尝试了另外一种柔性可用的方法。我们的需求是验证码能够在几分钟内有效,我们也可以计算,手机号加上当前时间戳,实际是 unix seconds 变成 unix minutes,算当前是多少秒分钟。通过手机号加时间,在它发的时候算 code,输入就是手机号加 unit,输出给它一个 code。

第二步,用户输入手机号传过来手机号加 code,假设配置是 5 分钟有效,计算其中的时间,拿手机号加上当前的时间,假设是 5 分钟,递减 5 分钟,当前的分钟数和手机号算一个值与 code 对比,不对的话最多循环五次(当然这个也有优化之处)。
当极端情况 cache 不可用的时候,我们可以手机号以及时间,通过内部的算法算出验证码是否基本可符,降级之后安全级别会一定降低,在可用性和安全性方面取得一个折衷。(编者:假如在系统正常情况下,cache 的验证码可以通过算法再加一个随机因子,严格符合才能通过,这样正常时候安全级别是可以有保证。)
攻击者有两种攻击,一种拿着手机号,换不同的 code,这是一种攻击。另外一种攻击,拿固定的 code 换不同的手机号,我们现在结合的方式,我们现在还是采用第一种,当我们后端服务不可用,还有兜底方,当然牺牲了一点点安全性。当我挂掉那段时间,我还是照样可以登录。
5. 高可用与异地多活
讲一下异地多活,保证系统永远可登录。在滴滴,由于业务发展太快,下图是当前业务分布的情况,它带给我们的一些麻烦。

上面是当前 Passport 简单的图解,我们现在是有 3 IDC,每一个 IDC 里面部署不同的业务,我们滴滴还没有做到业务异地多活。可能 IDC1 有专车快车,IDC2 有顺风车,IDC3 里面有代驾。
我们现在是租用的机房,一个 IDC 如果机器不够用,就从别的机房匀出一些,导致我们的业务非常分散,这也给 Passport 和账号团队的服务提出挑战,我们要提前业务做异地多活。但是现在业务本身并没有做到异地多活。
我们把登录实现了多活,注册还没做,但是目前已经足够满足我们要求,如果一个机房挂掉只是影响新注册的用户,在一定程度是可以接受的,所有其它的服务可保证正常使用。
刚才提到不同的 IDC 存在不同的业务。一个人登录进来,先用快车在 IDC1,点开顺风车在 IDC2。这里面就有一些很细节的东西,也就是刚才说 ticket 问题。用户用户在 IDC1 登录,IDC1 给他一个 ticket,这个时候 IDC2 里的 ticket 并没有更新,因为我们所有的请求都是在同机房完成。这时候切到另外一个 IDC 校验,如果当前的 seq 比它传过来,而且发现比他当前小的情况,可以考虑放行。这是由于有可能同步的延迟,seq 还没同步过来。通过这个柔性可用策略,一定程度解决了多机房数据同步不一致的问题。
6. 独立的访问控制层——Argus
我们部门所有的服务都是平台级的业务,比如账号支付,所有业务线都要访问,一般都是通过内网来访问。
为什么要做过载保护?当公司业务部门增多后,会碰到不同的业务拿到线上做压力测试的情况,我们现在所有的公共业务部署,不是按业务线多地部署,我们是大池子大集群,每个业务线都来混合访问。账号访问由于容量比较大,一般压测并没有引起问题。但是在支付的时候,做压力测试在线上支付,就可能会直接把支付拖挂。
我们想必须有一种机制,不能相信任何的业务方,它随时能犯错误,需要通过技术手段去解决。因此需要有过载保护,包括权限控制等一系列机制等。

如上图,防控就是 Argus 系统,承载了过载保护,白名单、安全策略等等职责。它是独立的服务,所有的业务流量打过来,都需要通过它做过滤。
上面提到现在业务并没有多机房的部署,因此如果需要对调用方进行 QPS 的限制?只需要通过在 cache 里设置一个配额,每调一次检验一次。
但这样有个问题,调用量太大。比如说快车有千万级别调用,调用量比较大,我给快车的某一个核心业务一个配额,如果都放在单个实例是支撑不住。因此可以增加一个简单的散列的方式,比如每个调用方调用的时通过 hash 到不同的 Argus 节点上。比如配额是十万 QPS,则可以部署 10 个节点,Argus 每一个就是一万,这样访问就比较可控了。
7. 接口拆分
刚才说的核心登录功能,不经常变,我们希望最稳定的接口独立出来,目的是让稳定不变更的部分故障率降低,所以需要考虑进行拆分。
核心的接口包括登录这一块,其实不经常变,但是像一些小逻辑,策略会经常跟着去上线,但大部分事故都是上线引起的。
分享一个 Pass-TT 的案例。当时跟快的合并时候,快的所有业务在阿里,滴滴所有的服务在深圳腾讯机房,ticket 服务在内网,两个机房跨公网,改造太大了,并且延时不可以接受。
所以我们设计了一个方式,简单说,登录从我们这边登录,访问快的服务的时候再给它 ticket,token。这个 token 专门为代驾用的,但是设计时候犯了一个错误,就是 RSA 方式进行加密。因为有一个远程校验,为了不想 key 泄漏,所以用 RSA 的方式,他们那边部署了一个公钥,我们这边是私钥,token 用我们的私钥加密,然后到它那边进行解密就 OK 了。

这些 token 失效是通过有效期,就是几个小时,失效后就用 ticket 来换。
结果一上线,由于端上有一个 bug,然后所有的等于 ddos 攻击一样,不停闪。当时 Passport 服务器还比较少,10 台左右的服务,正常 CPU 利用率大概在 30% 不到,那个接口一上一下子到 70%,眼看全要挂了,然后连夜我们赶快把那样一个接口单独拆出来,打到不同的单元上,然后重新部署。
所以给大家一个建议,当用 SOA 的时候,如果你的量特别大的时候,你一定要记得把它的 CPU 占用非常高那些功能及接口提前单独拆分出来。
高可用的效果
更多得益于 golang 本身,我们去年在线单机 QPS 峰值超过一万,现在我们有更多的机房,滴滴整个的订单去年和今年都是有数倍增长。
我们响应时间,我们的所有接口无论获取用户信息或者是校验,其实是非常小的,目前高并发接口小于 5 毫秒。密码相关的接口是在 200 毫秒,这主要加解密本身的耗时。
总结
滴滴跟前面分享的今日头条非常相似,发展太快,四年的时间,滴滴的技术规范完全没有统一,文嵩加入滴滴之后,有机会再做服务治理包括框架统一,但是这件事可能会比较挑战,目前滴滴的技术体系特别异构,PHP、Java、Golang 都有,因此目前也不能太多从系统层面给大家做分享,以后应该有这样的机会。
后面有一句话,什么是一切为了高可用?针对 Passport 账号这种系统,需要有柔性的降级,可能需要一些巧妙设计,包括多机房。
one more thing
被攻击的问题
再补充一个被攻击的问题。其它的系统被攻击相对好一点,账号给你挡了,登录后再攻击,至少有 ticket 给你挡了。
发短信攻击,这个维护费用是非常巨大的,攻击者目的你并不知道,他就是要你不停发短信,曾经被这个东西搞得焦头烂额。
当然可以做一些蜜罐的机制,当发现有异常,返回正常值,让攻击者觉得正常,其实服务端什么也没做,这是蜜罐机制。要真正解决这类问题,跟安全部一起做了试点,端上做这种是比较简单,认证比较容易。但是在 app 上不好做,通过 JavaScript 算,其实比较麻烦,并且容易别识破。另外还可以做一些人机识别机制。
Q&A
Q:token 什么时候更新?
洪泽国:token 只有两种失效机制,一个是用户重新登录,第二个踢掉,现在参照微信的做法,端上定期会拿着来换一次。
Q:密码更新,所有的 token 都失效 如何解决?
洪泽国:密钥一更新,登录都踢出?这个问题之前的确有讨论过,有两种方式,第一,让它失效,所有人重新登录,并不是完全不能接受,对用户来讲就是重新登录,密钥泄漏是一次事故。第二,看紧急程度,当前哪些人登录,比如先把没有登录的踢掉,后端算出来,对于已经有的,然后慢慢踢。新的在入口的时候,就要给它打到新的一套服务里面去,你要做新老两套密钥服务之间的切换,并且在上线是知道。
Q:HttpDNS 作用?
洪泽国:HttpDNS 从入口层面上就决定了所有的这一个请求全部落在这个机房,而不会存在两个 IDC 之间内部错峰的一切交替,不会你这个故障某一个服务我就打到那边。HttpDNS 比较简单,维护的信息比较少。无非就是一个服务对应一个IP列表,这是动态,这是很容易做的,信息不会太多。
Q:切换 IDC 怎么做,数据你怎么复制?
洪泽国:我们的确在讨论这样的方式,我不太确认是不是能够最完美回答你的问题,我们现在方案通过 HttpDNS 做中转,通过它我能够完成这件事情,第二,怎么发现故障,这里面包括两个问题,一个是怎么发现 IDC 挂了。第二,发现后怎么做,发现后 HttpDNS 很容易给一个新地址。第一个问题怎么发现,我们内部也在尝试一些方法,可能更多通过手段的方式,或者通过检测链路故障,无非触发时机,所有的链路故障都是从系统,网络层面上触发的。只要 HttpDNS 提供一个接口,一旦故障给它打个标记,A 故障,HttpDNS 就返回 B,这是很容易做到。但是怎么判断它是故障,这是一个问题。这个更多从网络层面去触发。
Q:刚才说如果其它服务链路问题导致 Web 失效,把用户踢下去,对于这种情况你们怎么处理,不是你本身的问题。
洪泽国:这个是调用方有约束的,调网络错误不应该是提的,更多是要从业务层面上,端和业务系统的配合形成。它调一个业务,业务调我,业务调我超时了,现在好多业务处理不是那么完美,出错也踢掉这是不合理的,我们跟他梳理,只有失效踢出是最合理。如果没有的话就踢掉,短信服务提供商那边压力是比较大的,做柔性降级。
[转]从密码到token, 一个授权的故事
1. 我把密码献给你
小梁找到信用卡达人张大胖试用 : “你的信用卡那么多,看看我这个程序吧, 保准你会爱死它。”
张大胖尝试了几下说: “咦,你这个程序要读取我的网易邮箱啊,那需要用户名/密码吧”
“是啊 , 你把密码告诉输入程序不就行了, 我的程序替你加密保存,保证不会泄露。”
“得了吧你, 我可不会告诉你我的密码, 为了方便记忆, 我的密码都是通用的, 万一泄露了就完蛋了”
小梁说:“这样吧,我不保存,我就访问邮箱的时候使用一次, 用完就扔!”
“你以为你是阿里巴巴啊, 有信用背书, 你只是个小网站, 我把密码献给你,总是觉得不安全。就是我信任你,别人能信任你吗?”
小梁想想也是, 这是一个巨大的心理障碍, 每个人都要誓死捍卫自己的密码啊。
过了一周, 小梁兴致勃勃地把张大胖拉来看“信用卡管家”的升级版。
“升级为2.0了啊, 这次不用问你要网易邮箱的用户名和密码了”
“那你怎么访问我的邮箱?”
“很简单,我提供了一个新的入口,使用网易账号登录, 你点了以后,其实就会重定向到网易的认证系统去登录, 网易的认证系统会让你输入用户名和密码,并且询问你是否允许信用卡管家访问网易邮箱, 你确认了以后,就再次重定向到我的‘信用卡管家’网站, 同时捎带一个‘token’ 过来, 我用这个token 就可以通过API来访问网易邮箱了。 在这个过程中, 我根本不会接触到你的用户名和密码,怎么样, 这下满意了吧?”
“你说得轻松, 你这个信用卡管家是个小网站,还没有什么名气, 网易怎么会相信你这个网站呢?”
“我当然要先在网易注册一下啊, 他们会给我发个app_id 和app_secret, 我重定向到网易的时候需要把这个东西发过去, 这样网易就知道是‘信用卡管家’这个应用在申请授权了。”
(点击看大图)
张大胖说: “ 你这重定向来重定向去的, 实际上不就是为了拿到一个token 吗?”
“对啊,因为你不信任我的信用卡管家, 不让它保存你的密码,只好用token的方法了 , 它是网易认证中心颁发的,实际上就代表了你对信用卡管家访问邮箱的授权,所以有了这个token 就可以访问你的邮箱了”
“对了” 张大胖问题, “你为什么用Javascript的方式来读取token啊”
“这样我的后端服务器就不用参与了,工作都在前端搞定, 你注意到那个URL中的#号了吗? www.a.com/callback#token=<网易返回的token>”
张大胖说: “我知道啊,这个东西叫做hash fragment, 只会停留在浏览器端, 只有Javascript 能访问它,并且它不会再次通过http request 发到别的服务器器, 我想这是为了提高安全性吧。”
小梁说: “没错, 那个token非常非常重要,得妥善保存,不能泄露!”
“可是在第6步通过重定向,这个token 以明文的方式发送给了我的浏览器, 虽然是https ,不会被别人窃取,可是浏览器的历史记录或者访问日志中就能找到, 岂不暴露了?”
小梁说: “这个…. , 我说你这个家伙,安全意识很强烈嘛, 让我想想,有没有更安全的方式。”
3. Authorization Code + Token
又过了一周,小梁成功地把信用卡管家升级为3.0.
他对张大胖说: “这次我成功地把那个非常重要的、表示授权的token 给隐藏起来了, 你要不要看看?”
“你先说说你是怎么隐藏的?”
“其实整体思路和之前的类似,只是我引入了一个叫做Authorization Code 的中间层。 当你用网易账号登录的时候, 网易认证中心这一次不给我直接发token,而是发一个授权码(authorization code) , 我的信用卡管家服务器端取到这个code以后,在后台再次访问网易认证中心, 这一次他才发给我真正的token 。 还是直接上图吧:”
(点击看大图)
张大胖说: “还比较容易理解, 本质上就是你拿着这个返回的授权码在服务器后台‘偷偷地’完成申请token 的过程, 所以token 浏览器端根本就接触不到,对吧?”
“什么叫偷偷地申请token ? 这是我信用卡管家服务器和网易之间的正常交流, 只是你看不到而已。”
“开个玩笑了, 你虽然隐藏了token,但是这个授权码确是暴露了啊,你看第7步,我在浏览器中都能明文看到, 要是被谁取到, 不也是照样能取到token吗?”
小梁说: “我们肯定有防御措施, 比如这个授权码和我的信用卡管家申请的app_id,app_secret关联, 只有信用卡管家发出的token请求, 网易认证中心才认为合法; 还可以让授权码有时间限制,比如5分钟失效,还有可以让授权码只能换一次token, 第二次就不行了。 ”
“听起来似乎不错, 好吧, 这次我可以放心地使用了!”
4. 后记
本文讲的其实就是就是OAuth 中的三种认证方式,依次是:
1. Resource Owner Password Credentials Grant(资源所有者密码凭据许可)
2. Implicit Grant(隐式许可)
3. Authorization Code Grant(授权码许可)
还有一种叫做Client credentials ,用的较少,文章没有涉及。