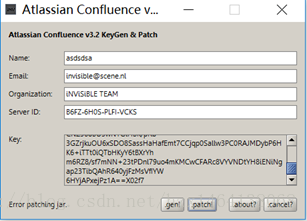
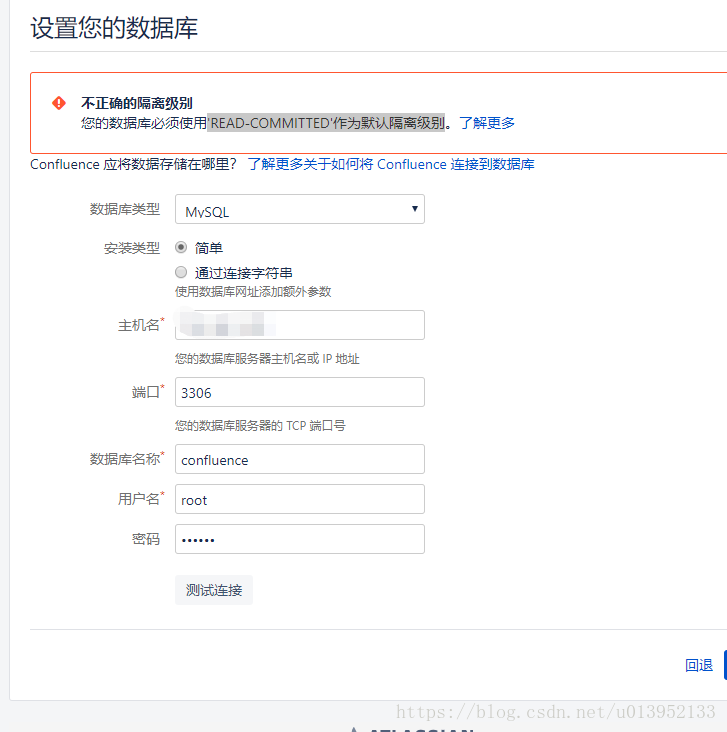
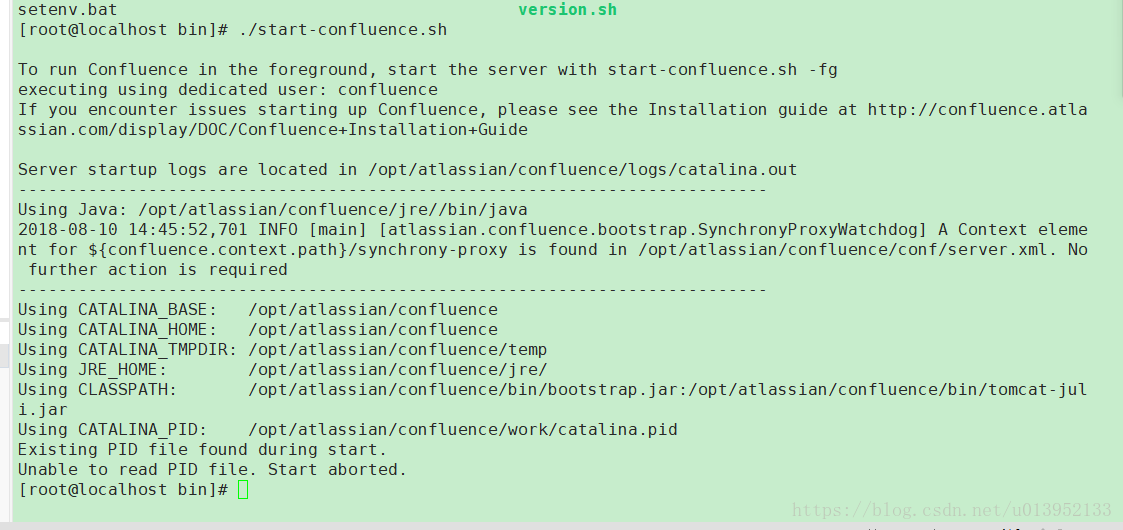
实现延迟消息最主要的两个结构:
环形队列:通过golang中的数组实现,分成3600个slot。
任务集合:通过map[key]*Task,每个slot一个map,map的值就是我们要执行的任务。
原理图如下:
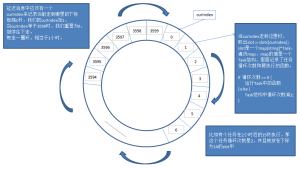

实现代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
|
package main;import ( "time" "errors" "fmt")//延迟消息type DelayMessage struct { //当前下标 curIndex int; //环形槽 slots [3600]map[string]*Task; //关闭 closed chan bool; //任务关闭 taskClose chan bool; //时间关闭 timeClose chan bool; //启动时间 startTime time.Time;}//执行的任务函数type TaskFunc func(args ...interface{});//任务type Task struct { //循环次数 cycleNum int; //执行的函数 exec TaskFunc; params []interface{};}//创建一个延迟消息func NewDelayMessage() *DelayMessage { dm := &DelayMessage{ curIndex: 0, closed: make(chan bool), taskClose: make(chan bool), timeClose: make(chan bool), startTime: time.Now(), }; for i := 0; i < 3600; i++ { dm.slots[i] = make(map[string]*Task); } return dm;}//启动延迟消息func (dm *DelayMessage) Start() { go dm.taskLoop(); go dm.timeLoop(); select { case <-dm.closed: { dm.taskClose <- true; dm.timeClose <- true; break; } };}//关闭延迟消息func (dm *DelayMessage) Close() { dm.closed <- true;}//处理每1秒的任务func (dm *DelayMessage) taskLoop() { defer func() { fmt.Println("taskLoop exit"); }(); for { select { case <-dm.taskClose: { return; } default: { //取出当前的槽的任务 tasks := dm.slots[dm.curIndex]; if len(tasks) > 0 { //遍历任务,判断任务循环次数等于0,则运行任务 //否则任务循环次数减1 for k, v := range tasks { if v.cycleNum == 0 { go v.exec(v.params...); //删除运行过的任务 delete(tasks, k); } else { v.cycleNum--; } } } } } }}//处理每1秒移动下标func (dm *DelayMessage) timeLoop() { defer func() { fmt.Println("timeLoop exit"); }(); tick := time.NewTicker(time.Second); for { select { case <-dm.timeClose: { return; } case <-tick.C: { fmt.Println(time.Now().Format("2006-01-02 15:04:05")); //判断当前下标,如果等于3599则重置为0,否则加1 if dm.curIndex == 3599 { dm.curIndex = 0; } else { dm.curIndex++; } } } }}//添加任务func (dm *DelayMessage) AddTask(t time.Time, key string, exec TaskFunc, params []interface{}) error { if dm.startTime.After(t) { return errors.New("时间错误"); } //当前时间与指定时间相差秒数 subSecond := t.Unix() - dm.startTime.Unix(); //计算循环次数 cycleNum := int(subSecond / 3600); //计算任务所在的slots的下标 ix := subSecond % 3600; //把任务加入tasks中 tasks := dm.slots[ix]; if _, ok := tasks[key]; ok { return errors.New("该slots中已存在key为" + key + "的任务"); } tasks[key] = &Task{ cycleNum: cycleNum, exec: exec, params: params, }; return nil;}func main() { //创建延迟消息 dm := NewDelayMessage(); //添加任务 dm.AddTask(time.Now().Add(time.Second*10), "test1", func(args ...interface{}) { fmt.Println(args...); }, []interface{}{1, 2, 3}); dm.AddTask(time.Now().Add(time.Second*10), "test2", func(args ...interface{}) { fmt.Println(args...); }, []interface{}{4, 5, 6}); dm.AddTask(time.Now().Add(time.Second*20), "test3", func(args ...interface{}) { fmt.Println(args...); }, []interface{}{"hello", "world", "test"}); dm.AddTask(time.Now().Add(time.Second*30), "test4", func(args ...interface{}) { sum := 0; for arg := range args { sum += arg; } fmt.Println("sum : ", sum); }, []interface{}{1, 2, 3}); //40秒后关闭 time.AfterFunc(time.Second*40, func() { dm.Close(); }); dm.Start();} |
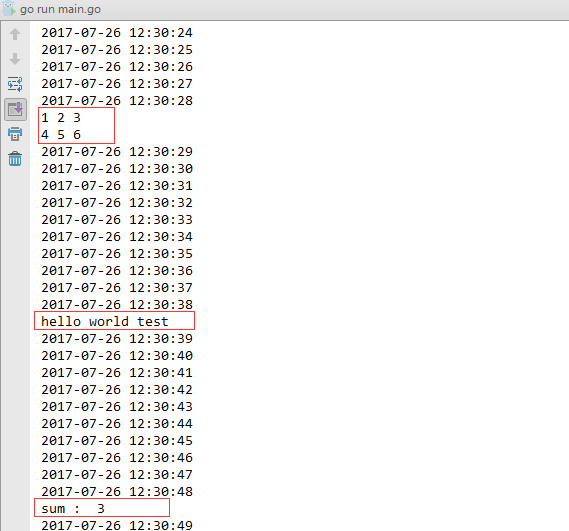
测试结果如下: